代码基模与 Agentic Training 前沿:从 GLM-5.2、DeepSeek-V4 到 SWE Agent RL
一份更像读论文现场的深度笔记:用 alphaXiv、论文图和官方技术报告,把代码基模、长上下文、verifier、SWE 环境和 agent RL 的训练闭环讲清楚。
这篇文章不是模型新闻列表,也不是为了证明我"懂很多新模型"。我真正想整理的是另一件事:代码基模正在从单函数 code generation,走到 repo-level、tool-use、long-horizon 的 agentic engineering。这个变化对软件工程研究者很实在,因为很多训练问题的源头不在模型结构,而在任务、数据、环境、verifier 和反馈预算。
我这次主要用 alphaXiv 的 paper/overview 页面复习论文,再对照 arXiv HTML 里的原图和官方技术报告页面。这样读起来比只看 PDF 更顺,图也更接近论文现场。下面每一节我都会尽量按同一个顺序写:
- 这篇材料到底在解决什么问题。
- 图里应该看哪几个细节。
- 它的训练 recipe 或系统 recipe 是什么。
- 我不完全买账或需要小心的地方。
- 它怎么接回我的 CodeAnchor、To Run or Not to Run、RepoRescue、AtomicCommitBench、SWE-OpenHarmony 这些工作。
如果只想带走一句话,我会这样概括:现在的 code model 不只是在比谁会写函数,而是在比谁能在真实软件仓库里持续工作;而持续工作需要的不只是更大模型,还需要可执行环境、结构化上下文、稳定 verifier、可靠轨迹和能承担成本的训练系统。
1. 先把训练语言对齐
我先把最底层的几个概念放在前面。原因很简单:读 GLM-5、DeepSeek-V4、Kimi K2 这类报告时,如果 loss、perplexity、attention、KV cache、SFT、DPO、RLVR 这些词还只是"听过",后面的模型报告很容易读成营销稿。
1.1 cross entropy、perplexity 和 pass rate 不是一回事
大模型预训练通常是 next-token prediction。给定上下文,模型输出 vocabulary logits,softmax 后得到下一个 token 的概率分布。对一个真实 token y,如果模型给它的概率是 p(y),单点交叉熵就是:
CE = -log p(y)
训练时会对大量位置取平均。loss 越低,说明模型越能把概率分给真实文本。perplexity 通常是 exp(loss),直觉上可以理解成模型平均每一步面对的"有效候选数"。如果 loss 是 2,perplexity 大约是 7.39;如果 loss 是 1,perplexity 大约是 2.72。这个解释不完美,但面试里够用。
真正容易混的是另一件事:pretraining loss 下降,不等于 SWE-bench resolved rate 一定上升。
loss 是 token-level objective。SWE-bench resolved rate 是一个长程任务结果。中间隔着很多环节:找文件、理解 issue、定位 bug、编辑 patch、跑测试、读日志、修失败、避免破坏其它行为。一个模型可能在代码语料上 loss 更低,但在真实仓库里仍然不会用工具,或者会把上下文塞满却找不到关键文件。
所以我现在更喜欢把 code agent 成功率拆成:
- base model 懂不懂代码和自然语言;
- repo context 是否给对了;
- trajectory 是否教会模型用工具;
- verifier 是否可靠;
- execution feedback 是否值得花;
- 推理时是否有足够但不过量的 search/test budget。
这也是为什么我的 To Run or Not to Run 不能只叫"执行测试策略"。放到训练语言里,它是在问 execution feedback 作为 observation/reward 的边际收益。
1.2 attention 和长上下文:能塞进去,不代表能用出来
decoder-only Transformer 的 causal self-attention 可以粗略写成:
softmax(QK^T / sqrt(d)) V
Query 表示当前位置要找什么,Key 表示历史 token 怎么被匹配,Value 是真正被聚合的信息。causal mask 保证模型预测当前 token 时不能看未来。
推理时,历史 token 的 Key/Value 会缓存下来,这就是 KV cache。它让自回归推理不用每一步重算所有历史 token,但代价是上下文越长,KV cache 越大。到了 128K、200K、1M context,问题就不只是"显存够不够",还包括带宽、attention FLOPs、prefill 延迟、以及上下文里噪声太多时模型是否还能定位证据。
这点和代码任务非常贴。真实 SWE agent 的上下文可能包括 issue、repo 文件、搜索结果、测试输出、失败日志、之前的修改、自己的反思。1M context 的确提高上限,但如果没有结构检索、文件锚点、调用关系、测试相关性排序,它也可能只是把更多无关 token 放到模型面前。
CodeAnchor 在这个语境下就不是传统静态分析的小工具。它更像 deterministic anchors:在长上下文里给模型一组稳定的结构入口,减少盲搜。
1.3 SFT、DPO、RLVR:代码任务为什么适合做 verifier
SFT 教模型模仿高质量示范。对 code agent 来说,示范不是一句答案,而是 observation-action 轨迹:搜索、打开文件、编辑、运行测试、读日志、提交 patch。
DPO 用 chosen/rejected pair 调偏好。代码里 chosen/rejected 很自然:通过测试、改动小、解释清楚的 patch 可以是 chosen;失败、删测试、过度修改、引入回归的 patch 可以是 rejected。
RLVR 更吸引人,因为代码任务有天然 verifier:unit tests、编译、lint、静态检查、运行输出。问题也在这里。SWE agent 的 reward 往往很稀疏:最后通过是 1,不通过是 0。它不告诉你哪次搜索有效,哪次测试值得跑,哪次修改只是碰巧没炸。环境还很贵,每次 rollout 都要容器、依赖、测试和超时控制。
我读下面这些论文时,一直用这组判断做尺子:它们改的是模型还是训练信号,扩大的是上下文还是上下文信噪比,增加的是 rollout 数量还是让每一次 rollout 更值钱。
1.4 三个小自测,先把答案写死
问题 1:能不能写出 CE = -log p(y)?
答案:可以。这里的前提是单个预测位置的真实 token 是 y,模型给这个 token 的概率是 p(y)。交叉熵就是 -log p(y);训练语言模型时,会对序列中大量预测位置取平均。p(y) 越接近 1,loss 越接近 0;p(y) 越小,loss 越大。
问题 2:perplexity 到底是什么?
答案:perplexity 通常是 exp(平均 NLL loss)。直觉上,它表示模型在每一步面对的"有效候选数"。比如 loss 从 2 降到 1,perplexity 从约 7.39 降到约 2.72,说明模型更能把概率集中到真实 token 上。但这个数仍然是 token-level,不是任务级正确率。
问题 3:loss 和 pass rate 为什么不完全一致?
答案:loss 优化的是下一个 token 分布,pass rate 衡量的是一个任务有没有完成。SWE agent 要跨过 repo retrieval、bug localization、patch editing、test execution、log reading 和多轮修复。模型可能 loss 更低,却仍然不会定位文件;也可能生成语言更顺,却在测试反馈面前乱改。把这两个数混为一谈,会把训练目标和真实软件任务之间的距离抹掉。
2. GLM-5 / GLM-5.2:agentic engineering 不是一句口号
GLM-5 的题目很直接:GLM-5: from Vibe Coding to Agentic Engineering。我喜欢这个题目,因为它把这两年代码模型的变化说得很白:从人类不断提示模型写一小段代码,变成模型自己读、改、跑、修、再验证。alphaXiv 的 overview 也基本沿着这条线来讲:先看模型规模和 benchmark,再回到训练管线、长上下文、RL infra 和 agentic tasks。对我来说,真正该截图进博客的不是阅读网页,而是论文里面能解释这条线的图。
论文里几个数字值得记:
- GLM-5 是 744B total / 40B active 的 MoE,比 GLM-4.5 更大。
- 训练 token budget 到 28.5T。
- 用 DeepSeek Sparse Attention (DSA) 降低长上下文训练和推理成本。
- 继续使用 slime 作为 post-training / RL 基础设施,把 rollout serving 和 training 解耦。
- 任务覆盖 reasoning、coding、agentic、terminal 和 long-horizon 工程任务。
我不建议只背这些数字。更值得看的其实是 Figure 5,也就是训练管线。
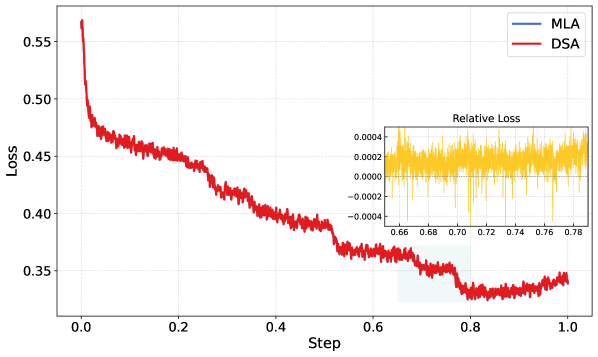
这张图的读法是:GLM-5 不是"预训练完再随便 SFT 一下"。它把 base training、mid/long-context training、SFT、reasoning RL、coding RL、agent RL、general RL 串成了一个多阶段过程。对 code agent 来说,后面的 RL 阶段不是锦上添花,而是在把模型从会回答题,推向会在环境里行动。
我会把这张图拆成三层来记。最底层是 base model:它负责语言、代码、数学和通用推理的底座。中间是 long-context 和 instruction 数据:模型开始适应更长的上下文、更复杂的任务格式。最上层才是面向能力的 post-training:reasoning RL、coding RL、agent RL 和 general RL 分别处理不同的反馈来源。这个顺序很重要,因为真实 SWE agent 的失败通常不是单点能力不足,而是几个环节一起掉链子:基础代码理解不稳、上下文组织不稳、工具轨迹不稳、verifier 也不稳。
这里有两个细节我会在面试里主动说。
第一,DSA 的价值不是让论文多一个结构创新,而是让长上下文 agent 变得算得起。SWE agent 的一次任务可能不是一个 prompt,而是几十轮工具调用。如果每轮都带很长上下文,attention 成本和 KV cache 成本会直接变成 serving 成本。
第二,slime 这类异步 RL infra 说明了一个现实:agentic post-training 的瓶颈不只是算法。rollout 太慢、环境太贵、tail latency 太长,都会让训练吞吐掉下来。报告里提到 server-based rollouts、Prefill-Decode disaggregation、fault tolerance,我读到这里的感觉是:现在 code model 训练组越来越像半个系统组。
第三,GLM-5 把 agentic task 的环境构造也写进了报告。软件工程任务、终端任务、搜索任务、幻灯片生成任务,各自有不同 verifier 和 rollout 形态。这个细节很重要,因为它说明 post-training 不再是统一的"给回答打分"。SWE 里 reward 可能来自测试;搜索里 reward 可能来自多跳答案验证;slides 里 reward 还要看渲染和视觉质量。agentic RL 的难点正是多任务、多环境、多 verifier 同时存在。
我还会注意它的 "thinking" 设计。报告里提到 interleaved thinking、preserved thinking、turn-level thinking 这些概念。对普通聊天来说,这可能只是风格控制;对长程 agent 来说,它关系到模型是否能在多轮工具调用之间保留问题状态。如果每轮都把思考清空,模型容易忘记前面为什么这么改;如果完整保留,又会把上下文越拖越长。所以这里其实是 long-context memory 和 agent control 的交界点。
GLM-5 的另一个值得学的地方是它把 benchmark 分得很细:reasoning、coding、agentic、terminal、long-horizon engineering 都是不同维度。它没有只靠 HumanEval 这类短代码题证明自己。这对我写简历也有启发:不能只说"我做程序修复",而要说我处理的是 repo-level navigation、execution feedback、verifier 和 long-horizon trajectory。
GLM-5.2 的 alphaXiv 页面 GLM-5.2: Built for Long-Horizon Tasks 又把这条线往长任务推进了一步。它强调 1M-token context、IndexShare、flexible reasoning effort 和 speculative decoding 相关优化。这个方向和 GLM-5 的关系很清楚:GLM-5 把 agentic engineering 作为目标,GLM-5.2 继续补长上下文和长程任务的系统能力。
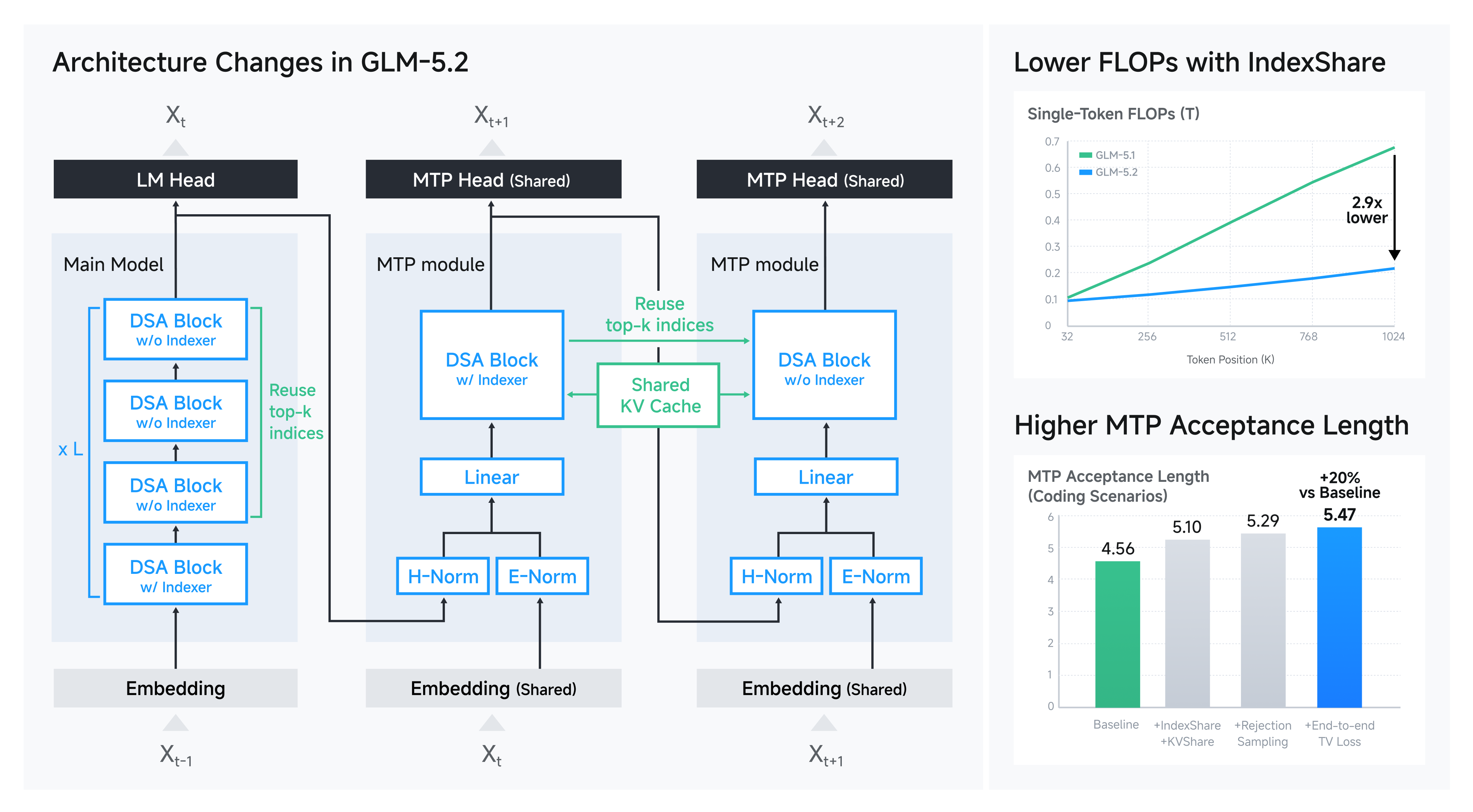
这张 alphaXiv 处理过的图比单纯的 benchmark 表有用。左边讲的是结构:主模型里只保留少数带 indexer 的 DSA block,后面的 DSA block 复用前面算出的 top-k indices;MTP module 则通过 shared head、shared embedding 和 shared KV cache 减少多 token prediction 的额外成本。右边讲的是结果:IndexShare 把长上下文下的 single-token FLOPs 压下来,MTP 相关改动把 coding 场景里的 acceptance length 往上推。
这其实是在回答一个很工程的问题:长程 agent 不是只要"能看 1M token"就行,还要每一步生成都便宜一些。否则 repo-level task 里几十轮 search/edit/test 叠起来,prefill、decode、KV cache 和环境开销会一起爆掉。
我会把 IndexShare 翻译成更口语的说法:不是每一层都重新决定"该看哪些历史 token",而是让少数 indexer block 先挑出重要位置,后面的 block 复用这个选择。这样做当然会引入一个风险:如果前面的 top-k 选错,后面复用也会错。但它换来的好处是长上下文下的 attention 成本更可控。对 agent 来说,这种 trade-off 很真实:我们一直在用近似和压缩换可用性。
MTP 这边则对应 decode 速度。coding agent 很多时候要生成长 patch、长命令、长解释,单 token 解码太慢会让 test-time scaling 成本变高。MTP acceptance length 提升,意味着 speculative decoding 能一次接受更多 token。它不直接改变模型是否懂 repo,但会改变多 rollout 和长会话是否负担得起。
把它接回自己的工作时,CodeAnchor 可以接到 long-context repo understanding;To Run or Not to Run 可以接到 agent rollout 和执行反馈预算;RepoRescue/SWE-OpenHarmony 可以接到可执行环境构造。也就是说,我不是只做"应用层 benchmark",而是在做 agentic engineering 需要的任务侧基础设施。
我也会保留一点警惕。模型报告里的 benchmark 很多,Terminal-Bench、Vending-Bench、SWE 相关任务都很热,但模型到底是不是学会了稳定工程推理,还要看任务是否泄漏、环境是否可复现、失败轨迹是否被分析。只看平均分,很容易把 agent 的偶然成功当成能力。
3. DeepSeek-V4:1M context 的问题是经济性
DeepSeek-V4 现在也可以直接从 alphaXiv 读:DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence。这比只看官方 release 更适合复习,因为 alphaXiv 的 .md 入口能把报告正文直接交给 AI 做二次提问。我更建议先看 Figure 1:左边是 benchmark,右边才是这篇报告最想让你记住的东西。
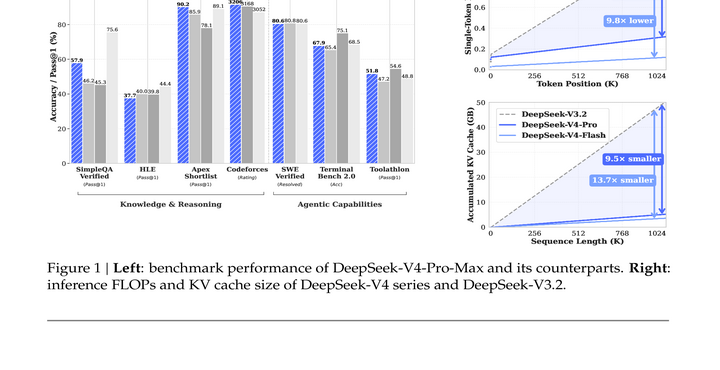
报告开头列出的核心信息包括:
- DeepSeek-V4-Pro:1.6T total / 49B active parameters。
- DeepSeek-V4-Flash:284B total / 13B active parameters。
- 两个模型都面向 1M context。
- 架构上用 Compressed Sparse Attention (CSA) 和 Heavily Compressed Attention (HCA) 做 hybrid attention。
- 引入 Manifold-Constrained Hyper-Connections (mHC) 和 Muon optimizer。
- 报告称在 1M context 下,V4-Pro 的单 token inference FLOPs 约为 DeepSeek-V3.2 的 27%,KV cache 约为 10%。
我把它放在 GLM-5.2 后面读,是因为两者都在回答同一个问题:长上下文不是宣传口径,而是 agent serving 的成本问题。DeepSeek-V4 的 Figure 1 右侧很直白:序列长度往 1M 走时,FLOPs 和 KV cache 如果还是接近线性猛涨,长程 agent 的 test-time scaling 会先被成本卡住。报告给出的 27% single-token FLOPs 和 10% KV cache 不是孤立数字,它们是在给 1M context 的日常使用找经济性。
对代码 agent 来说,1M context 至少会遇到四个问题。
第一,prefill 成本。把一个大仓库、日志、历史 action 全塞进去,第一步生成前就已经很贵。
第二,KV cache。多轮推理时,缓存越来越大,batching 和内存管理都会变难。
第三,证据定位。长上下文里有更多噪声,模型可能"看到了"关键文件,但 attention 没有落到那里。
第四,反馈预算。运行测试和保留日志都能提供信号,但它们也会继续拉长上下文。
这就是我觉得 DeepSeek-V4 对 SWE agent 的启发:它让"长上下文经济性"变成一个必须认真回答的问题。我的 To Run or Not to Run 可以翻译成同一类判断:哪些 observation 值得花环境成本换回来,哪些日志继续放进上下文反而会降低信噪比。
DeepSeek-V4 也提醒我,不要把 1M context 讲成单纯的"能塞更多代码"。它真正关心的是每个历史 token 的表示成本、检索成本、cache 成本和服务吞吐。如果未来 code agent 每个任务都带着几十轮工具轨迹,那么上下文长度本身会变成训练和推理预算的一部分。
DeepSeek-V4 的架构关键词可以这样记:CSA/HCA 处理的是 attention pattern,mHC 处理的是深层网络的信息流,Muon optimizer 处理的是训练效率和稳定性。它们不在同一个层面,但服务同一个目标:让大模型在更长 context、更大规模参数和更低推理成本之间找到可训练、可部署的折中。
CSA 和 HCA 对我来说最像一个分层记忆系统。不是所有历史 token 都值得以同样精度保存,也不是所有历史位置都要参与同样密度的 attention。代码仓库里也一样:issue 标题、失败测试、调用入口、最近 patch 可能需要高优先级;README 的长段落、无关模块、重复日志可以被压缩或丢弃。模型架构在做的事,和 agent context manager 在做的事,其实是同构的。
再细一点,CSA/HCA 不是在回答"模型能不能记住 1M token",而是在回答"每个历史 token 值多少钱"。传统 dense attention 把历史 token 放在同一个计算平面里;压缩或稀疏 attention 则承认一个事实:长上下文里大部分 token 只需要提供粗粒度背景,少数 token 才需要被高精度访问。repo-level agent 也是这样。一次修 bug 时,package lock、README、无关测试文件不应该和 failing stack trace、目标函数、调用入口享受同样预算。
mHC 我会放在另一个层面理解。长上下文不只是 attention 瓶颈,深层网络的信息流也会变得难训。报告里把 hyper-connections 写成更稳定的信息传递结构,核心是避免深层模型在极长序列下只靠残差硬撑。这个点我不敢过度解读,但它提醒我:长上下文报告里的结构改动往往是组合拳,不是一个 sparse attention 名词就解决所有问题。
Muon optimizer 则对应训练效率。Kimi K2 也会讲 Muon/MuonClip,所以这两篇可以放在一起复习:一个模型如果要在几十 T token 上训练,优化器的 token efficiency 和稳定性都会进入成本方程。读模型报告时,不要只问"参数多大",还要问"同样 token 和算力下,训练是否更稳、更省、更少 spike"。
我会把 Figure 1 的右侧当成这篇报告的核心,而不是左侧 benchmark。benchmark 告诉你它强不强,右侧成本图告诉你它为什么可能被大规模使用。1M context 如果每次生成都贵到不可用,就只能当演示;如果 FLOPs 和 KV cache 被压下来,它才可能支撑真实代码 agent 的多轮调试。
这里也有一个我不完全放心的点:长上下文 benchmark 往往不能完全代表 repo-level reasoning。模型在 needle-in-a-haystack 或长文问答上表现好,不等于它能在复杂仓库里知道哪个文件该改。软件仓库的难点不是只有距离长,还有结构复杂、测试间接、依赖隐式、历史状态多。DeepSeek-V4 解决的是底层经济性,CodeAnchor 和执行反馈调度解决的是任务侧信噪比。
所以这一节如果变成面试问答,我会这样回答。
问题:DeepSeek-V4 对代码 agent 的真正启发是什么?
答案:它把长上下文从"模型能力"改成了"单位成本"问题。1M context 对 repo task 有用,但只有在 attention FLOPs、KV cache、prefill 和日志噪声都可控时才有用。底层模型解决的是长会话经济性;任务侧还要解决结构检索、反馈保留、测试日志压缩和停止策略。
所以我会这样回答 DeepSeek-V4 的价值:它让我把 "context length" 从能力指标改写成成本指标。1M context 对 SWE agent 有意义,但前提是模型能负担得起长会话,并且我们有办法把关键证据组织进去。
4. IQuest-Coder-V1:把 code model 训练写成 pipeline
IQuest-Coder-V1 Technical Report 是这份清单里最贴近代码基模训练的一篇。它不像有些模型报告那样只给 benchmark 表,而是明确提出 code-flow multi-stage training。
这张图值得慢慢看。它把训练分成几块:
- pre-training 和 high-quality annealing:代码、文档、仓库、completion、FIM、repo evolution data。
- 32K mid-training:加入 reasoning、agentic trajectories 和 code tasks。
- 128K mid-training:把 repo-scale context 放进训练。
- bifurcated post-training:thinking path 更偏 reasoning/RL,instruct path 更偏通用助手。
- LoopCoder:用 loop transformer 变体做部署 footprint 和模型容量之间的折中。
我最关心的是"32K 到 128K"这个变化。它不是简单把 context length 拉长,而是把训练分布从单文件/短任务推到 repository-level reasoning。真实仓库任务的证据分散在 issue、文件、调用链、配置、测试和历史修改里。模型如果只学过短上下文代码补全,很难在 repo-scale 任务里稳定导航。
repo evolution data 是这篇里很值得抓的词。代码不是静态快照,它一直在 commit、PR、issue 和测试之间演化。一个训练样本如果只包含最终文件,模型学到的是"代码长什么样";如果包含变更前后、commit intent、patch diff、测试变化,模型才可能学到"为什么这么改"。这和 AtomicCommitBench 的价值直接相连。
FIM 也值得放进同一张图里理解。Fill-in-the-middle 教模型补中间缺口,和真实编辑很像,因为开发者经常不是从头写文件,而是在已有代码里插入或修改一段逻辑。单纯 left-to-right completion 对 repo editing 不够自然;FIM、patch data、repo evolution data 一起出现,说明 IQuest 在把代码生成任务往编辑任务靠。
32K mid-training 加 reasoning/agentic trajectories,我会理解成让模型先学会中等长度的闭环动作。128K 再放 repo-scale context,是把它推到更真实的仓库尺度。如果没有前面的轨迹训练,直接上长 context 可能只会让模型变成"会读很长 prompt 的代码补全器",不一定会行动。
IQuest 的 post-training 也很有意思。thinking path 和 instruct path 分开,说明代码模型已经不再是一个统一"会聊天的模型"就够了。你可以希望模型在复杂问题上显式推理,也可以希望它在工具场景里快速听指令,这两个目标可能需要不同的数据和 RL 配方。
thinking path 的意义在长程任务里尤其明显。一个 SWE agent 要先形成假设,再用工具验证,再根据结果修正假设。这个过程和单轮代码问答不同,它需要 error recovery。IQuest 把 thinking path 和 RL 放在一起,实际上是在说:复杂代码任务的能力不只是语言模仿,而是从失败中恢复的策略。
instruct path 也不能忽略。真实产品里的代码模型不是每次都要长思考。有些场景需要低延迟、格式稳定、遵循工具协议。把 thinking 和 instruct 分开,可能是为了在不同使用场景下控制成本和行为风格。这一点和 GLM-5.2 的 flexible reasoning effort 可以互相印证:未来 code model 可能不再是固定"深思考"或固定"快答",而是按任务动态分配推理预算。
LoopCoder 的存在则提醒我:并不是所有代码模型都只追求更大参数。部署 footprint、active compute、延迟、显存都重要。对于企业内部代码 agent,能不能在可控成本下部署,有时比多 1-2 个 benchmark 点更实际。
这篇对我的简历映射非常直接:
- CodeAnchor:repo-scale context 里的结构锚点。
- AtomicCommitBench:commit/patch evolution data 的任务来源。
- RepoRescue:可执行仓库修复环境。
- To Run or Not to Run:agentic trajectories 里的 execution feedback scheduling。
我会这样解释自己和 IQuest 这条线的关系:IQuest 这种训练 pipeline 需要高质量 repo tasks、agent trajectories、verifier 和低泄漏评测。我过去做的 SE 工作,正好可以提供这些训练信号,而不是只在模型外面做 demo。
需要小心的是,报告里的 code-flow 说法很漂亮,但真正落地时最难的仍然是数据质量。repo evolution data 如果没有严格去重和泄漏控制,很容易把 benchmark 变成记忆题;agent trajectories 如果只是强模型的漂亮演示,也可能教会模型冗长、低效或不可复现的路径。
我会给这篇的复习答案定成一句话:IQuest-Coder-V1 不是告诉我"多阶段训练很厉害",而是把代码模型训练拆成了数据演化、上下文扩展、轨迹学习、RL 推理和部署折中。它最适合拿来说明 SE 任务资产如何进入 code model pipeline。
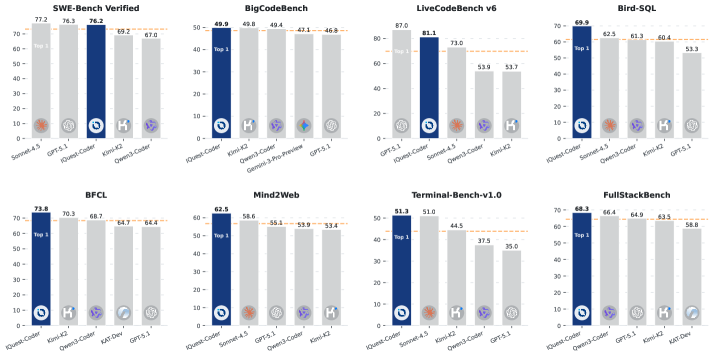
5. Qwen3-Coder:20,000 个环境不是装饰词
Qwen3-Coder 的官方博客 Agentic Coding in the World 给出的是开源 code model scaling 的另一条路线。它没有把重点全放在一个漂亮 leaderboard 上,而是反复强调一个训练事实:如果想让代码模型从 completion 走到 agentic coding,就要让模型在大量可验证环境里反复行动。
公开信息里最值得记的点有五个:
- Qwen3-Coder-480B-A35B-Instruct 是 480B total / 35B active 的 MoE。
- 原生 256K context,可通过 YaRN 扩到 1M。
- pretraining 使用 7.5T tokens,其中代码占比约 70%。
- post-training 强调 hard-to-solve but easy-to-verify 的 Code RL。
- 构建了 20,000 个并行环境支持 long-horizon RL。
这几个数字里,我最不想让读者机械背的是 480B/35B。它当然说明模型够大,但真正有训练含义的是"hard-to-solve but easy-to-verify"和"20,000 parallel environments"。前者定义任务形状:题目要难到模型不能靠模板直接答,验证又要清楚到测试、运行或比较器能给反馈。后者定义系统能力:训练不是在一台机器上慢慢跑 demo,而是要把数万个环境同时调度起来。
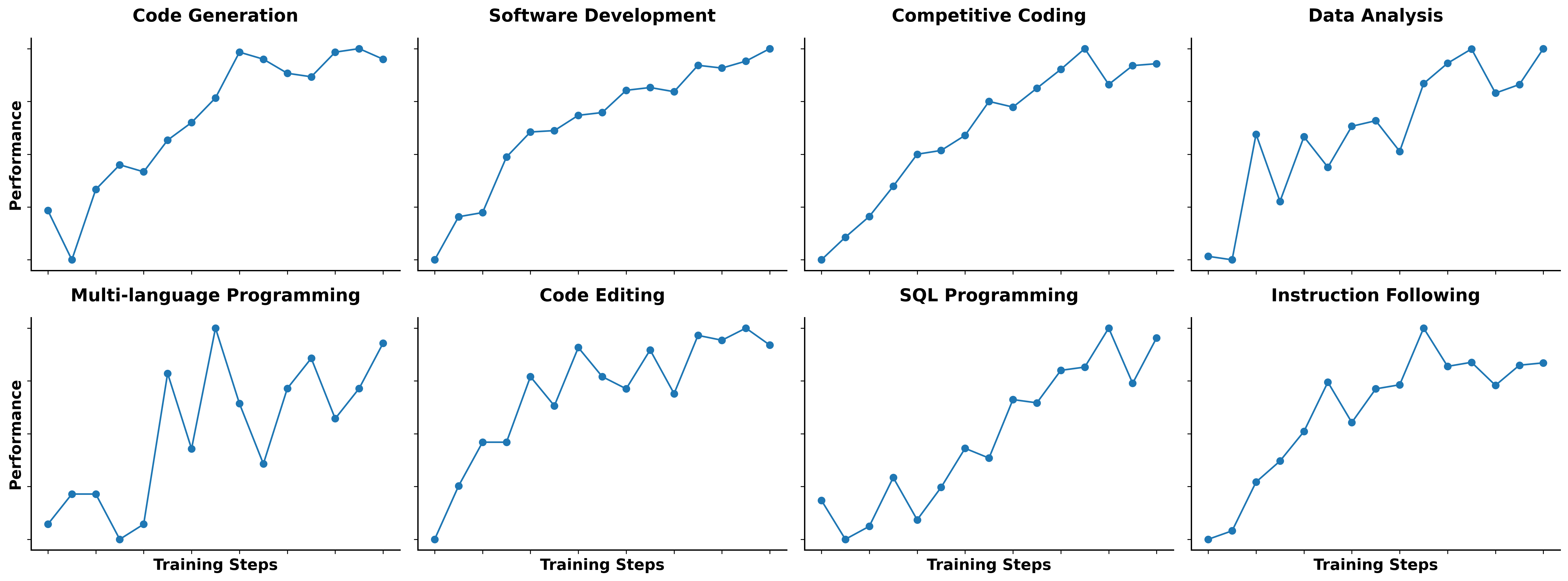
这张图适合拿来解释 Code RL 为什么不是只刷 SWE-bench。八个子图对应不同能力:code generation、software development、competitive coding、data analysis、multi-language programming、code editing、SQL programming 和 instruction following。曲线有的平滑上升,有的抖动明显,这反而真实。不同任务的 reward 噪声、样本难度、环境稳定性不一样,训练曲线不会像教科书一样整齐。
如果只看 software development 那个子图,它的意义不是"训练步数越多越好"这么简单。更准确地说,模型在反复接触可验证开发任务后,开始学到一些靠静态语料学不到的东西:什么时候搜索,什么时候打开文件,什么时候编辑,什么时候跑测试,测试失败后怎么读日志。这个能力很难完全来自 next-token pretraining,因为 pretraining 大多只看到最终代码和文本,不看到"改错了以后怎么恢复"。
20,000 并行环境背后还有一个训练系统问题。每个环境都要处理依赖安装、工作目录、测试命令、超时、日志截断、状态回滚和 reward 回传。任何一项做不好,都会污染训练信号。比如某些任务失败不是模型错,而是依赖装不上;某些任务通过不是修好了,而是测试太弱;某些 rollout 超时是因为模型迷路,也可能只是环境启动慢。对 RL 来说,这些都会进入梯度的背景噪声。
所以我会把 Qwen3-Coder 的 Code RL recipe 拆成一个更具体的检查表。
第一,任务要 hard-to-solve。模型不能靠静态补全或模板过关,否则 RL 只是把已有能力复述一遍。SWE 任务里,这通常意味着要跨文件定位、理解失败测试、改真实代码,而不是写一个孤立函数。
第二,任务要 easy-to-verify。这里的 easy 不是说任务简单,而是结果能被程序判断。测试、编译、SQL 执行、脚本输出、竞赛判题器都可以是 verifier。没有 verifier,RL 就退化成让 judge 猜一个长轨迹好不好。
第三,环境要便宜且稳定。20,000 个环境不是炫耀,它是在解决吞吐。一个环境如果启动 10 分钟、经常 flaky、日志格式不稳定,训练就会被系统噪声拖死。
第四,轨迹要能过滤。不是每条通过轨迹都值得学,也不是每条失败轨迹都没用。一个通过轨迹如果删了测试,应该丢掉;一个失败轨迹如果定位正确但 patch 少一个边界条件,可能能变成 preference 或 guidance 数据。
第五,能力要分桶看。图里的 software development、competitive coding、SQL、code editing 不该被合成一个平均分。不同任务的 verifier、动作空间、上下文长度都不同,训练曲线也会不同。平均分好看不等于 repo agent 稳。
我会把 Qwen3-Coder 这条线和 OpenHarmony 任务连起来看。Android 到 HarmonyOS 迁移、OpenHarmony app 修复、ArkTS 编译错误、UI 性能问题、依赖漂移修复,都可以构造成领域化的可执行环境。它们不一定替代通用 SWE-bench,但很适合提供低泄漏、可控、带 verifier 的训练/评测补充。尤其是 OpenHarmony 这种生态,公共训练语料相对少,垂域环境的价值会更高。
如果要把 OpenHarmony 做成 Qwen3-Coder 这种训练语言里的资产,我会先做三件事。第一,把任务分成可验证类型:编译错误、API 迁移、UI 行为、性能退化、依赖漂移。第二,为每类任务配稳定 verifier:hvigor build、单测、UI 自动化、性能计数器、静态规则。第三,把成功/失败轨迹记录成 observation-action-reward,而不是只保存最终 patch。这样它才不只是 benchmark,而是能进入 post-training 的环境资产。
这篇材料也提醒我,不能把"代码任务适合 RL"讲得太轻松。代码确实有测试,所以有可验证 reward;但 SWE 任务的测试经常不完美,环境经常 flaky,patch 可能过拟合,模型也可能学会删测试、改 harness、绕过检查。真正的难点不是"有没有 reward",而是 reward 是否可信、是否足够密、是否能支撑 credit assignment。
问题:Qwen3-Coder 的 20,000 环境到底说明什么?
答案:说明 code RL 已经不是小规模 prompt 实验,而是环境吞吐、任务验证、轨迹过滤和训练稳定性的系统工程。SE 研究如果能提供真实、稳定、低泄漏的可执行任务,就可能进入模型后训练闭环,而不是只做外部评测。
如果面试里问 Qwen3-Coder 给我什么启发,我会这样答:它说明 code model 的后训练正在从静态答案学习转向大规模环境交互。SE 研究能贡献的不是再写一个提示词,而是把真实软件问题做成高质量环境、测试、轨迹和 verifier。这个贡献很靠近训练闭环,不是在模型外面看热闹。
6. Kimi K2:我最想背的是 MuonClip 和合成环境,不是榜单
Kimi K2: Open Agentic Intelligence 很容易被读成又一个大 MoE 报告:1T total / 32B active,SWE-bench 分数,agentic intelligence。可我觉得最值得认真看的其实是两件事:pretraining stability 和 agentic data synthesis。
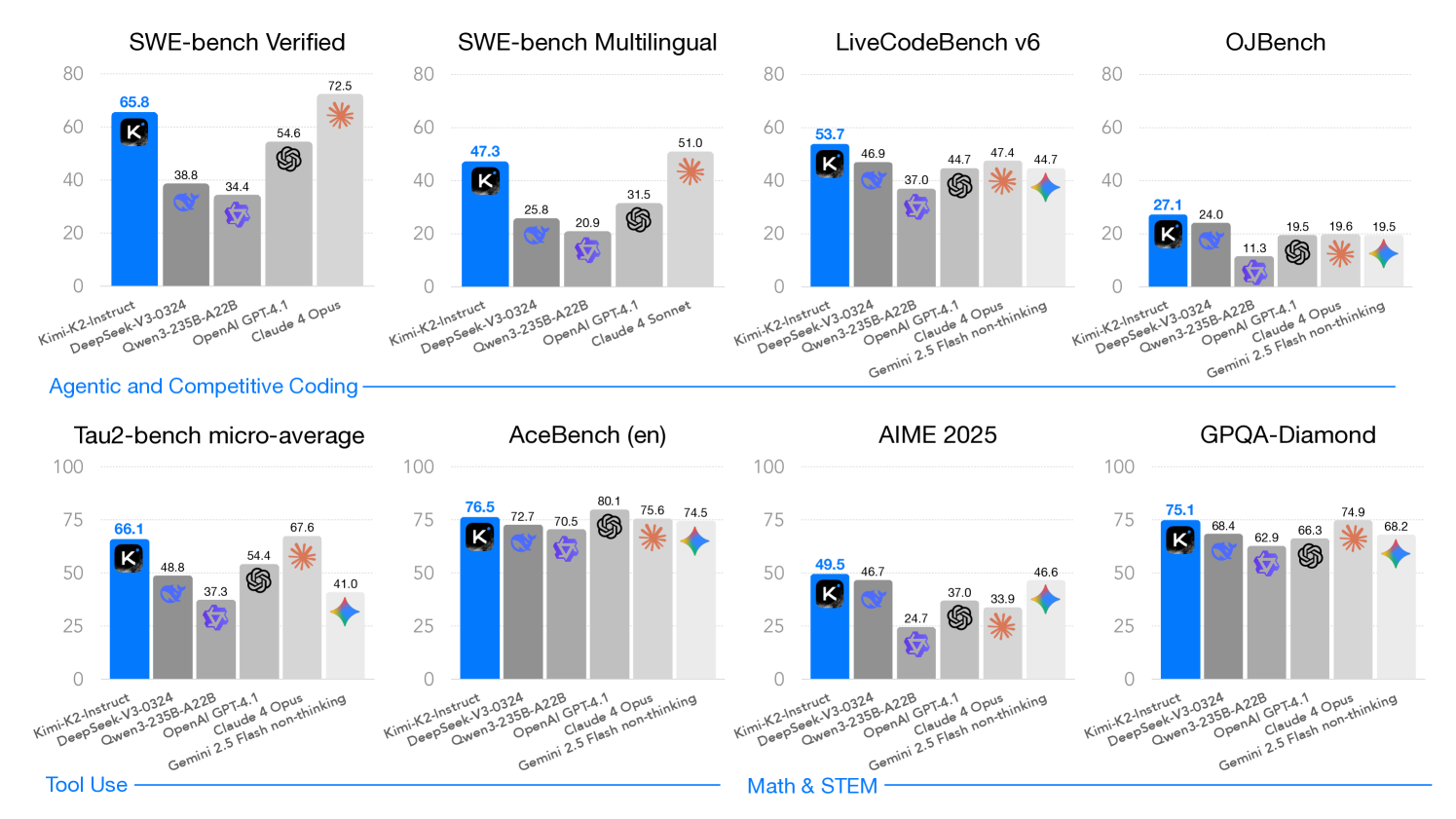
报告里说 Kimi K2 使用 MuonClip,在 15.5T token pretraining 中没有观察到 loss spike。这里的重点不是"zero loss spike"这句话有多好听,而是它把训练稳定性讲成了 attention dynamics 的问题。
Muon 本身是近来很受关注的优化器方向。Kimi K2 在它基础上加入 QK-Clip,控制 attention logits。图里左边显示 vanilla Muon 的 attention logits 很快冲到非常高的量级,右边显示 MuonClip 能把 logits 控在更稳定范围。对训练组来说,这比一个 benchmark 表更硬,因为 loss spike 往往不是一句"调小学习率"能解决的。
我会把这张图读成一个排查思路。训练大 MoE 时,如果 attention logits 不受控,softmax 会变得极尖,梯度也会不稳定。QK-Clip 的作用不是神秘地提高模型智商,而是把 query/key 投影造成的 logits 放到可控范围里。这样 Muon 的 token efficiency 才不至于被训练不稳定抵消。面试里如果被问 loss spike,我不会只说"学习率太大",而会按优化器、attention logits、梯度范数、数据 batch、混合精度和并行状态去排查。
Kimi K2 的另一条线是 agentic data synthesis 和 joint RL。报告里提到工具使用数据、合成工具、agent/task 组合、trajectory generation、LLM judge filtering,以及后续 verifiable rewards gym 和 self-critique。我的理解是:真实 agent 交互数据太贵,人工标注太慢,所以模型团队会越来越依赖可验证的合成任务和可回放环境。
这里有一个很值得展开的训练问题。
问题:合成 agentic 数据到底合成什么?
答案:不是只合成 prompt,也不是只合成答案,而是合成 tool spec、agent persona、任务目标、成功标准、环境状态、工具调用和多轮反馈。一个任务可能要求模型查库存、改文件、跑测试、调用 API,环境要在每次动作后更新状态。只有这样,模型才会学到"行动造成后果"。
Kimi K2 的合成管线值得多停一下。它不是简单让模型写一些"请帮我修 bug"的问题,而是先合成工具和任务,再合成 agent 轨迹,再用过滤和 verifier 挑出能用的交互。这个顺序很关键:如果没有工具定义,agent 学不到 action schema;如果没有环境状态,agent 学不到动作的后果;如果没有过滤,合成轨迹会把模型自己的坏习惯放大。
joint RL 也可以这样读:Kimi K2 想把外部可验证 reward 和更开放的 self-critique / rubric reward 放在一起。代码、数学、工具任务有明确 verifier;开放任务则很难写成单测,只能让模型或 judge 根据 rubric 评价。这个设计很现实,但也有风险。verifiable reward 过窄,模型会只学会刷测试;rubric reward 过软,模型又可能学会讨好 judge。
这和普通 SFT 的差别很大。普通代码 SFT 可能让模型看到一段需求和一段 patch;agentic synthesis 则让模型看到过程:它为什么选择这个文件、为什么调用这个工具、为什么某个测试失败后要回退。前者教答案形状,后者教行动策略。
我会把 Kimi K2 的 post-training 想成两种数据在拉扯。一边是真实或模拟环境里的可验证任务,它们给硬信号,但覆盖面有限;另一边是合成工具和自评数据,它们覆盖面广,但容易飘。好的训练 recipe 需要把这两边互相校准:合成数据负责规模,真实 verifier 负责刹车。
这和 AtomicCommitBench 的思路有点像。我们不一定能无限收集真实 issue,但可以构造带意图、顺序、patch、测试或验证信号的任务,让模型学习变更链路。难点是合成任务不能只有形式,它得保留软件工程里的因果结构。
我对 Kimi K2 的保留意见也很明确:agentic data synthesis 容易制造分布幻觉。如果工具、任务、轨迹都由模型合成,模型可能学会合成世界里的捷径,而不是真实 repo 里的工程约束。要缓解这个问题,就需要真实环境、真实测试、真实失败分析。这里正是 SE 研究能补进去的位置。
问题:Kimi K2 这一节到底该背什么?
答案:背两条线。第一,MuonClip 说明大规模训练的稳定性可以从 attention logits 和优化器机制解释,不要只会说 loss spike。第二,agentic data synthesis 说明后训练缺的是可规模化、可验证、可过滤的交互数据。SE 任务的价值在于给合成 agent 世界提供真实约束。
所以 Kimi K2 对我的启发有两层。第一,训练稳定性本身要懂,不然读模型报告只能背结果。第二,agentic data synthesis 需要真实软件工程约束来校准。AtomicCommitBench、RepoRescue、SWE-OpenHarmony 这类任务,如果构造得足够干净,就可以成为合成世界和真实世界之间的校准器。
7. SWE-Gym:训练环境的起点不是 prompt,而是可执行实例
SWE-Gym 是我认为所有 SWE agent training 都应该先读的一篇。它回答一个很基本但经常被低估的问题。
问题:什么叫一个可训练的软件工程任务?
答案:不是只有一个 issue prompt。一个可训练的 SWE task 至少要有:
- natural language task specification;
- codebase;
- executable runtime environment;
- unit tests;
- gold patch 或可验证目标;
- agent 交互轨迹或可生成轨迹的环境。
SWE-Gym 包含 2,438 个真实 Python task instances。论文还做了 SWE-Gym Lite,用于更快原型验证。
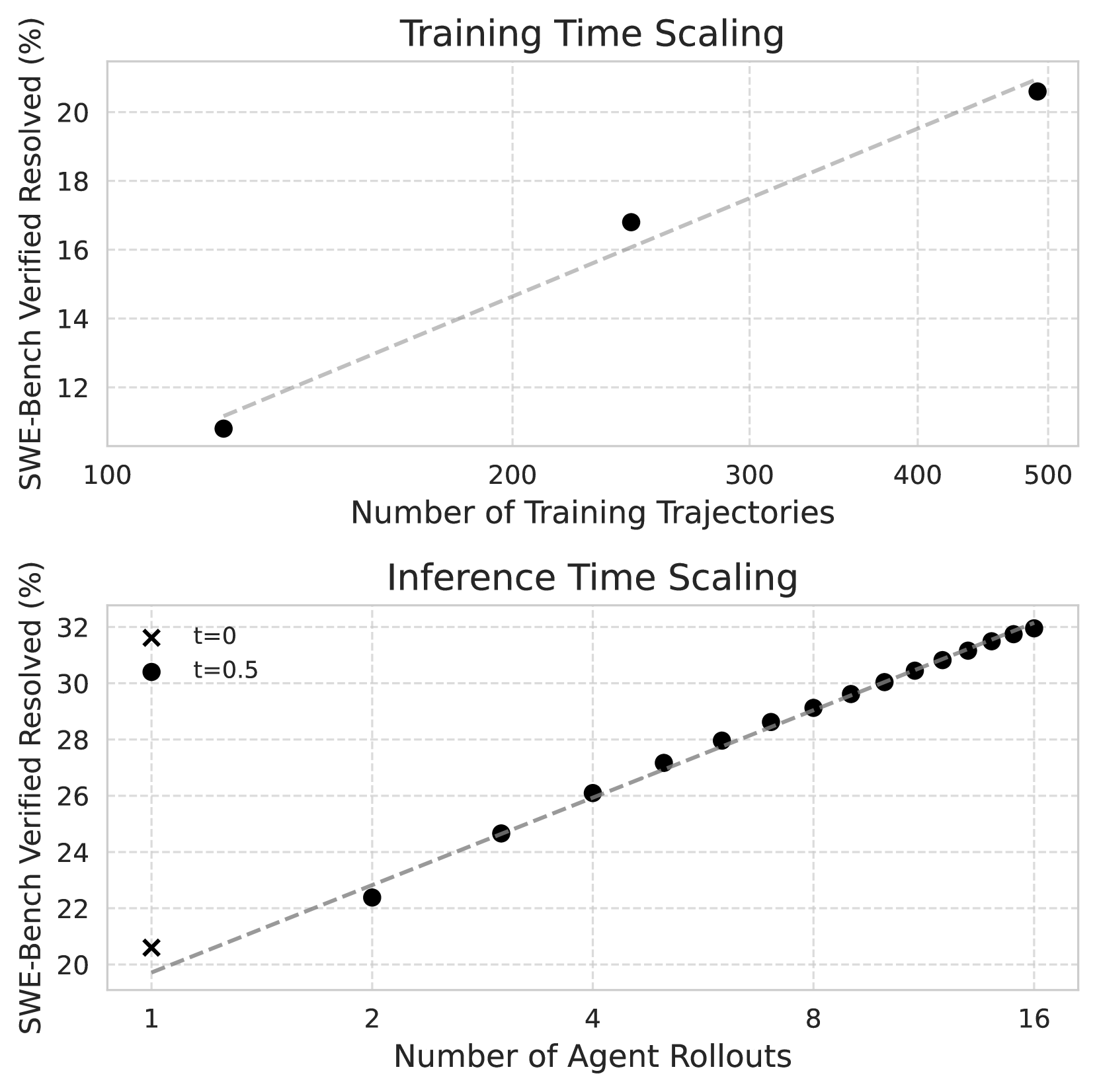
这张 Figure 1 很适合教学。上半部分说 training-time scaling:更多高质量训练轨迹能提高模型表现。下半部分说 inference-time scaling:推理时多采样、多 rollout、用 verifier 选解,也能提高 resolved rate。
图里真正要抓住的是 scaling 的资源来源。训练时间 scaling 需要任务和轨迹。轨迹从环境里跑出来,环境需要 Docker、依赖、测试和日志。inference-time scaling 需要多次尝试和 verifier。多次尝试会增加成本,verifier 质量又决定你选出来的是好 patch,还是碰巧过弱测试的 patch。
SWE-Gym 的方法论可以拆成三层。第一层是 instance construction:从真实 GitHub issue 和 PR 中抽取任务,配好 repo snapshot、gold patch 和测试。第二层是 agent trajectory collection:用强模型在环境里跑,收集成功和失败的轨迹。第三层是 training and verifier:成功轨迹可以用于 rejection sampling fine-tuning,成功/失败轨迹可以训练 outcome verifier,最后在推理时对多个候选 patch 排序。
这里有个很关键的观念:verifier 不只是评测器。它可以成为训练数据过滤器,也可以成为 test-time reranker。SWE-Gym 把 SWE agent 训练从"让模型自己写一个 patch"变成"生成多个候选、用轨迹级证据判断哪个更可能正确"。这和人类开发也接近:我们不会只看 diff 漂不漂亮,还会看测试、日志和修改路径是否合理。
更具体地说,SWE-Gym 的 verifier 学的是"这条轨迹最后可能成功吗",不是只看最终回答有没有像标准答案。它可以读 trajectory:模型搜了哪些文件、改了哪里、跑了哪些测试、失败后怎么处理。这样的 outcome verifier 对 inference-time scaling 很有用。多 rollout 以后,如果没有 verifier,pass@k 只是理论上界;有了 verifier,才有机会把多个候选 patch 排序。
SWE-Gym 还让我重新理解"训练环境"这四个字。一个环境不是一份数据集压缩包,而是能 reset、能执行、能返回 observation、能验证结果、能记录轨迹。没有 reset,rollout 不可重复;没有 execution,reward 是猜的;没有轨迹记录,SFT/DPO/RL 都拿不到过程信号。
这篇最适合补一个常见误解:SWE-bench 是评测集,不天然等于训练环境。一个 benchmark instance 放在那里,只能告诉你最后对不对;训练环境还要能反复 reset、执行、收集 observation、记录 action、过滤失败轨迹。SWE-Gym 的贡献正是把这套基础设施公开化。
SWE-Gym 的贡献是把 SWE agent 从"prompting proprietary model"推进到"open-weight model 可以在公开环境里训练"。没有可执行环境,RLVR、DPO、verifier reranking 都会变成纸上谈兵。
我最警惕的点是污染和可复现。SWE-bench 系列任务已经非常有名,训练数据里是否见过相关 issue、patch、测试、讨论,都需要严肃处理。环境也可能因为依赖版本变化而不可复现。RepoRescue 在依赖漂移上的工作,可以很好地接到这个问题。
还有一个小但很实在的问题:SWE-Gym 的训练规模现在仍然受 trajectory sampling 成本限制。论文里能看到随着训练轨迹增加还有收益,这说明瓶颈可能不只是任务数量,而是你能跑出多少可靠轨迹。对训练组来说,这会立刻变成环境吞吐和预算问题。对我来说,这也解释了为什么执行反馈调度不是细枝末节:每次运行测试都在消耗采样预算。
问题:SWE-Gym 和 SWE-bench 的差别是什么?
答案:SWE-bench 更像评测终点,SWE-Gym 更像训练场。前者告诉你一个 patch 最后有没有解决任务;后者提供可执行环境、测试、轨迹采样和 verifier 训练信号,让 open-weight 模型可以从环境交互里学习。
如果把这篇接回自己的研究,我会说:To Run or Not to Run 是 SWE-Gym 之后的问题。SWE-Gym 让执行环境变得可用,但执行环境不是免费 oracle。测试是否该跑、该跑哪些测试、失败日志是否该回填上下文,都会影响成本、上下文噪声和训练轨迹质量。
8. SWE-smith:数据规模不是抓更多 GitHub
SWE-smith 处理的是 SWE-Gym 之后的另一个痛点:真实 SWE agent 训练数据太少,构造太贵,环境太重。
论文构造了 50k+ task instances,来自 128 个 GitHub repositories。它还把存储问题讲得很具体:如果沿用 SWE-bench 那种 image-per-instance 思路,同样规模可能需要几十 TB 到上百 TB;SWE-smith 通过 repository-level environment 设计,把规模化变得更现实。
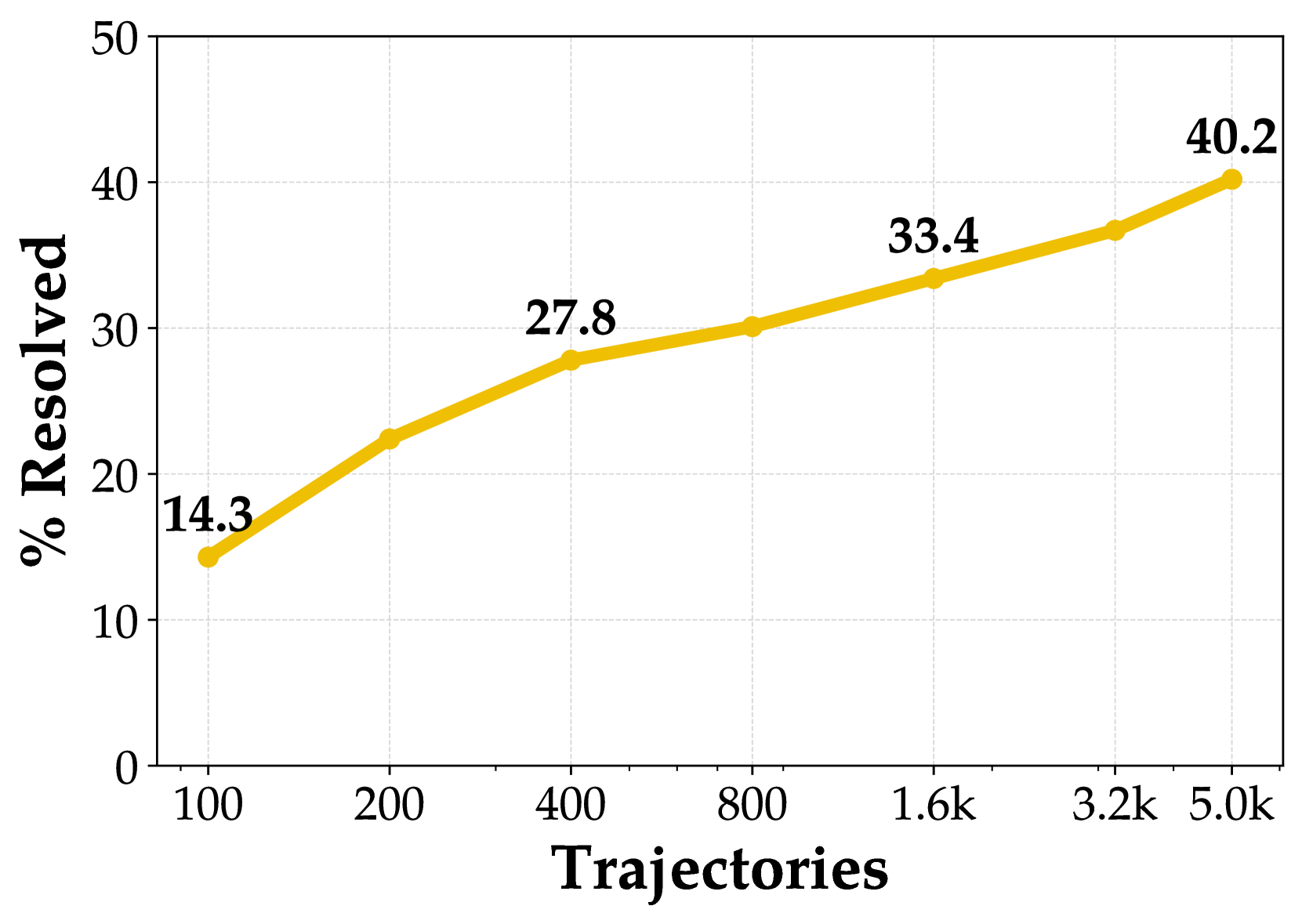
这张图是我最想拿来讲 benchmark-to-training 的。它不是从 issue 收集开始,而是从 codebase 开始,自动设置环境,再通过多种策略生成 bug,让原本通过的测试失败,然后再构造 agent 要修复的任务。
这里有一个值得记住的转变:benchmark 不只是评测终点,也可以是训练数据来源。一个 task instance 如果有环境、有 failing tests、有目标行为、有可验证修复,就可以进入 SFT、DPO、RLVR 或 verifier training。
我会把 SWE-smith 的流程分成五步读。
第一步,先选 repo,而不是先选 issue。它从 PyPI/GitHub 里挑活跃 Python 项目,目标是让每个 repo 有一个可复用环境。这个选择改变了成本结构:环境搭好以后,同一个 repo 可以生成很多 task。
第二步,构造 repository-level environment。这里很不性感,但最重要。安装命令、测试命令、依赖版本、Docker image、通过率阈值,任何一个环节不稳,后面的训练数据都会坏。
第三步,合成 bug。论文里用了 LM Modify、LM Rewrite、procedural modification、Combine Bugs、PR Mirror 等策略。它们对应不同成本和难度:procedural modification 便宜但可能模板化,PR Mirror 更接近真实 PR 但成本高,Combine Bugs 可以制造多位置、多函数任务。
第四步,用现有测试做 execution-based validation。只有引入 bug 后能让原本通过的测试失败,任务才有 fail-to-pass 信号。这个步骤让任务不只是"看起来像 bug",而是真正能被测试抓住。
第五步,生成 GitHub issue 风格的问题描述,再用专家模型生成成功轨迹,做 rejection sampling fine-tuning。最终训练出来的 SWE-agent-LM-32B 在 SWE-bench Verified 上达到 40.2% Pass@1,这个结果说明合成数据不是只能当玩具。
这五步里最反直觉的是第一步。很多人会先找 issue,再努力给每个 issue 搭环境。SWE-smith 反过来:先把 repo 环境搭稳,再在里面批量造任务。这个 inversion 很工程,也很聪明。因为 SWE 训练数据最贵的不是写一句问题描述,而是让代码真的能装、能跑、能测、能重复。
bug 生成策略也不能只看数量。LM Modify 便宜、产量高,但可能生成比较局部的错误;LM Rewrite 可能改得更深,但成本更高;Procedural Modification 几乎免费,却容易模板化;PR Mirror 更贴近真实软件演化,但成本和成功率都更难控;Combine Bugs 能制造多点故障,但也可能让任务不自然。不同策略产出的训练信号不一样,不能混在一起只报一个 50k。
issue text 生成也是难度控制器。如果问题描述直接暴露 failing test、目标函数和修复意图,agent 的 localization 难度会被削掉;如果描述太模糊,任务又可能不可解。SWE-smith 用 F2P test 和执行输出来生成 GitHub-style issue,这很实用,但也意味着 issue 文本本身可能携带训练偏差。模型学到的是"由测试反推的 issue 风格",不完全等于真实开发者提 issue 的方式。
但是 SWE-smith 也暴露出合成任务的老问题。合成 bug 如果太模板化,模型会学模板;测试如果太弱,模型会学 reward hacking;issue 描述如果由模型生成,可能和真实开发者提 issue 的风格不一样。规模化不等于真实,50k 也不自动等于高质量。
我尤其在意一个细节:SWE-smith 的任务适合训练,但不一定适合直接当 benchmark。因为 fail-to-pass tests 可能在仓库里可见,issue 生成也可能泄漏过多定位信息。训练任务和评测任务的设计目标不同,不能混用。训练任务可以暴露更多学习信号;评测任务必须更小心隐藏答案和控制污染。
这篇对数据工程还有一个启发:repository-level environment 降低的不是一点点存储,而是整个数据扩展模式。如果 50k instance 都要 image-per-instance,维护成本会先爆;如果同一个 repo 共享环境,就能把更多预算放在任务生成、轨迹采样和质量过滤上。这个思路对 OpenHarmony 也适用:先搭稳定项目族环境,再批量生成或收集迁移/修复/性能任务。
我会把自己的 benchmark 经验这样翻译给基模训练同学听:我关心的不是"又做了一个排行榜",而是如何构造低泄漏、可执行、可回放、带 verifier 的 code tasks。这样的任务可以评测,也可以进入训练。
SWE-smith 还给了一个很现实的失败诊断:很多 agent 失败在 localization,甚至在修改代码之前就卡住;还有不少失败轨迹表现为重复动作。这个观察和 CodeAnchor 非常贴。结构锚点不是为了让模型显得更懂静态分析,而是为了减少 blind exploration,把 agent 从"一直看同一个文件"拉出来。
问题:SWE-smith 为什么不是"合成数据越多越好"?
答案:它真正的价值在环境优先和 execution-based validation。多只是结果,不是保证。合成 bug 要能让真实测试 fail-to-pass,issue 文本要控制难度,轨迹要过滤,训练集和评测集要分开。否则 50k 任务也可能只是 50k 个会诱导模型学捷径的样本。
9. SWE-Dev:训练 scaling 和 inference scaling 要一起看
SWE-Dev 的标题是 Building Software Engineering Agents with Training and Inference Scaling。它把两个经常分开讨论的问题放到一起:训练时如何扩数据,推理时如何扩交互预算。
论文从大量 PyPI/GitHub 资源中筛选仓库和实例,构造 SWE-Dev 数据,并用合成测试用例和扩展 agent trajectories 做训练。它报告 7B 和 32B SWE-Dev 模型在 SWE-bench Verified 上分别达到 23.4% 和 36.6% resolved rate。
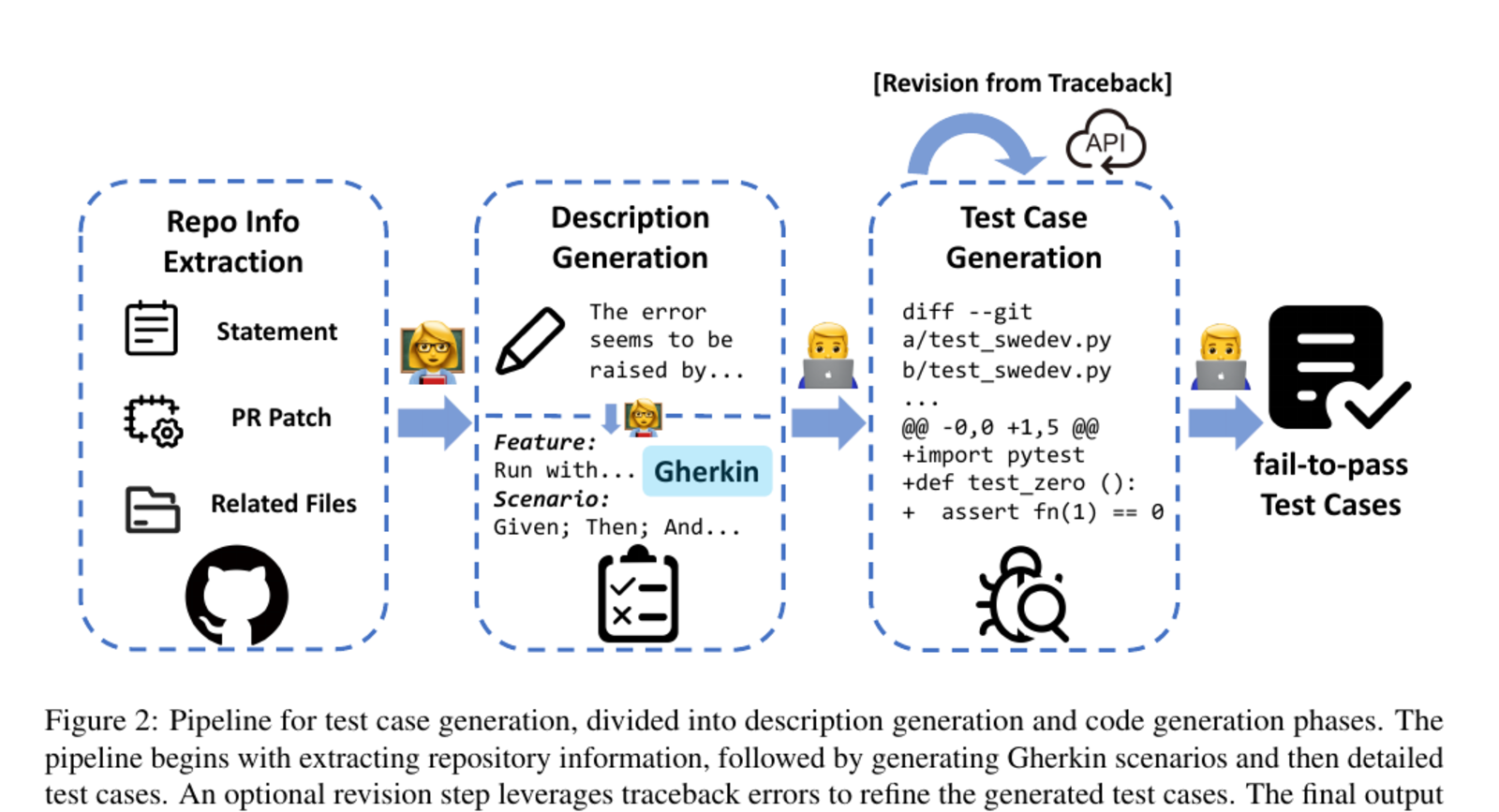
这张图是 SWE-Dev 最该被截图出来的部分。它解释了为什么这篇论文不是简单"多收一点轨迹"。SWE 训练数据的瓶颈往往是测试,而不是 issue 文本。没有测试,就没有可靠 verifier;没有 verifier,RFT、DPO、RL 都很难知道哪个轨迹值得学。
图里的 pipeline 可以分成四段。
第一段是 repo information extraction。模型先拿到 statement、PR patch、related files 等信息。这一步相当于给测试生成模型提供上下文。如果上下文抽错,后面的测试即使能运行,也可能测不到真正行为。
第二段是 description generation。论文用 Gherkin 作为中间表示,也就是 Given/When/Then 风格的测试场景描述。我觉得这个设计很聪明,因为直接让模型写 pytest 容易一口气把意图和代码都写乱;先写自然语言场景,可以把"要测什么"和"怎么写测试代码"拆开。
第三段是 test case generation。这里再把 Gherkin 场景和 repo 上下文转成具体 diff/test code。图上还有 revision from traceback,说明生成测试不是一次性完成的,而是根据报错回修。
第四段是 fail-to-pass validation。一个好测试应该在原始代码上失败,在修复后通过。这个 F2P 性质是软件工程训练数据的黄金信号,因为它比"看起来合理"强得多。
我读 SWE-Dev 时主要盯三件事。
第一,测试用例生成。SWE agent 的 reward 很依赖 tests。测试太弱,模型会过拟合;测试太强或不稳定,模型拿不到有效信号。测试生成不是辅助步骤,而是 verifier 质量的核心。
第二,trajectory expansion。扩轨迹并不是简单让模型多跑几次。要决定哪些轨迹可学、哪些失败轨迹可作为反例、哪些 observation 要 mask 掉、哪些工具调用只是噪声。
第三,inference budget。给 agent 更多轮数通常能提高上限,但也会放大成本和错误机会。更多交互不等于更好,尤其当模型会陷入重复搜索、不断运行同一组测试、或在错误文件里越改越远时。
SWE-Dev 的训练结果也要细读。7B 到 32B 有提升,数据规模增加也有提升,RFT 在论文实验里比一些离线 RL 方案更稳。这个结果并不反 RL,而是提醒我们:在 SWE agent 这种稀疏奖励环境里,先用高质量成功轨迹做行为初始化,可能比急着套复杂 RL 更可靠。离线 RL 如果正负样本分布不对,很容易学不到真正策略差异。
inference scaling 也很有意思。SWE-Dev 增加的是单次 run 内的 interaction rounds,而不是简单 pass@k 多抽几个独立答案。它更像给 agent 更长的思考和修复预算。论文报告 32B 模型从 30 rounds 到 75 rounds 有收益,但也出现边际递减。这个现象非常符合直觉:前几十轮可能帮助定位和修复,后面可能只是重复尝试。
这里要区分两种 scaling。training scaling 是把更多可学轨迹、测试和任务放进模型参数里;inference scaling 是推理时给模型更多试错机会。前者贵在数据构造,后者贵在每个用户请求的运行成本。SWE-Dev 把两者放在一起,提醒我们不要只追一个方向:训练数据不够时,多轮推理会迷路;推理预算太少时,训练出的策略也没有机会修正错误。
我还会特别看它的 F2P test。fail-to-pass test 是软件工程任务里少数很硬的信号:buggy version fail,fixed version pass。它比自然语言 judge 更可靠,但也更难生成。一个 F2P test 如果太贴近 gold patch,会泄漏答案;如果太弱,模型可能过拟合边角;如果 flaky,训练 reward 会变脏。测试生成这一环,实际上决定了后面 RFT/DPO/RL 的上限。
这正好接到 To Run or Not to Run。执行反馈不是免费资源。一次测试运行可能带来强信号,也可能只是浪费时间、污染上下文、诱导模型在弱测试上过拟合。SWE-Dev 告诉我们 training scaling 和 inference scaling 都有用;我的问题会被改写成一个预算策略:执行预算该花在哪一步,什么时候继续交互已经不划算。
问题:SWE-Dev 和 SWE-Gym/SWE-smith 放在一起看,差别在哪里?
答案:SWE-Gym 更像把真实 issue 变成可训练环境;SWE-smith 更像环境优先的规模化合成任务;SWE-Dev 则把测试生成、轨迹扩展和推理轮数放到同一个 scaling 问题里。它最适合用来说明 verifier 不是现成的,测试本身也需要生成、修复、验证和过滤。
如果要把这篇讲给别人听,我不会只说"它做到 36.6%"。我会说它把 SWE agent 的两个瓶颈接起来了:训练时缺测试和轨迹,推理时缺预算调度。前者靠 test generation 和 trajectory expansion,后者靠 iteration scaling。我的研究可以自然接在第二个问题上,也可以通过 OpenHarmony 场景补第一个问题的垂域测试生成。
10. Agent-RLVR:可验证 reward 不等于容易 RL
Agent-RLVR 的问题意识很直接:RLVR 在数学题、竞赛编程里有效,但到了 agentic environment,事情会难很多。
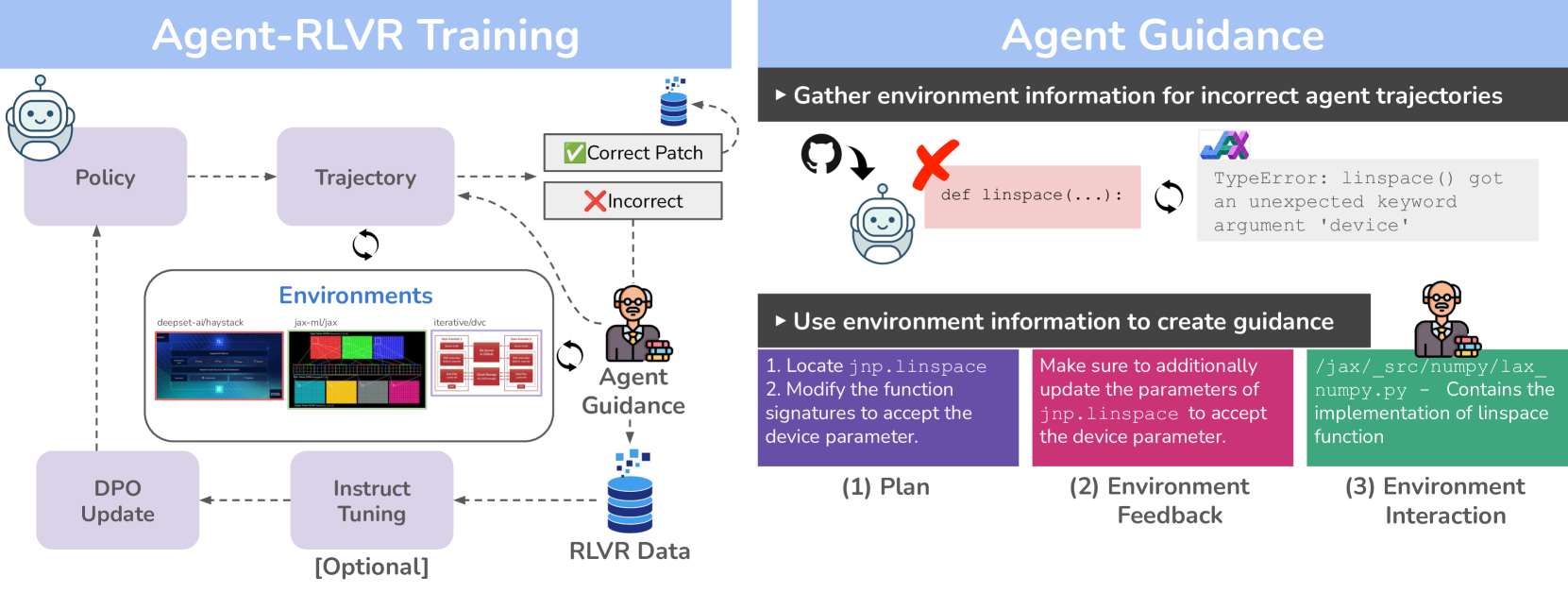
这张图可以分成两半看。
左边是训练 loop:policy 生成 trajectory,环境给 observation 和 reward,再用 DPO/RLVR 类方法更新模型。右边是 guidance:先收集环境信息,生成 guidance,把 agent 往更可能成功的方向引。
guidance 的必要性来自 SWE agent 的稀疏 reward。一个 episode 可能很长,最后失败就是 0。对模型来说,它不知道是搜索错了、文件读少了、patch 写错了、测试没跑、还是环境超时。正样本太少时,RL 很难学到东西。
论文里还包括 27 个 repos,593 个来自 SWE-Gym 的 problems 和 219 个自收集 problems。这个设置本身说明了一点:agent RL 的 task coverage 很难靠一个 benchmark 解决。真实训练需要多来源任务和环境。
我会把 Agent-RLVR 看成对 RLVR 乐观叙事的修正。代码任务有 verifier,所以适合 RL;但代码 agent 是长程交互,所以 RL 信号很稀疏。两句话都对,中间差的是 guidance、curriculum、trajectory filtering、verifier quality 和环境吞吐。
guidance 的价值在于降低探索难度。它可以来自 teacher model、失败 patch、测试输出、环境观察或人工/模型生成的提示。比如一个任务原始 issue 很模糊,agent 第一次 patch 失败后,guidance 可以告诉它"失败测试暴露的是边界条件,不是类型错误"。这样第二次 rollout 更可能走向正确区域。
这里要小心一个副作用:guidance 如果太强,就会把训练变成答案提示;guidance 如果太弱,模型还是不知道怎么改。好的 guidance 应该像调试线索,不像完整解法。它给方向,但不替 agent 做完定位和 patch。
Agent-RLVR 还把训练和测试时使用方式分开。训练时 guidance 帮助采到更多正确轨迹,再用正确/错误轨迹做 DPO 或 reward model;测试时可以不直接给 guidance,而是让训练过的模型自己执行。这样做的好处是避免部署时依赖额外标注,但它要求训练数据里的 guidance 真能迁移成策略,而不是只在训练 prompt 中生效。
论文里关于 reward model 的结果也值得记:RLVR 数据可以训练 test-time reward model,用于在多个 patch 中挑选更可能正确的候选。这个点和 SWE-Gym 的 verifier 思路一致。agent training 的数据不仅能更新 policy,也能训练 verifier;policy 和 verifier 是同一个数据闭环里的两种产物。
我会把 Agent-RLVR 的 loop 讲成四步。第一步,agent 先裸跑一次,生成初始 trajectory。第二步,环境用单测判断 patch 对不对,并从失败轨迹里收集错误信息。第三步,teacher 或 guidance module 生成线索,可能是高层计划、失败原因、相关文件、测试期望或下一步建议。第四步,agent 带着 guidance 重试,成功/失败轨迹再进入 instruct tuning、DPO 或 reward model 训练。
这里的 DPO pair 很直观:同一个问题下,通过测试的 guided trajectory 是 chosen,失败的是 rejected。它比人工偏好更硬,因为 preference 来自环境;但它也比数学题复杂,因为 chosen/rejected 不是一句答案,而是一整条多轮轨迹。轨迹里可能有多余搜索、错误尝试、无关日志,训练时还要决定监督哪些 action,mask 哪些 observation。
guidance 的来源也值得拆开。plan guidance 给路线,比如"先看 jnp.linspace 的签名";environment feedback 解释失败,比如"TypeError 来自 device 参数";environment interaction 则更像帮模型探索环境,告诉它哪些文件或测试相关。三者的强度不同。plan 最容易变成答案泄漏,feedback 最接近真实调试,interaction 最考验如何避免替模型做完任务。
CodeAnchor 在这里可以被看成一种 guidance:不是直接告诉答案,而是给模型更稳定的结构入口。execution feedback 则是 environment observation/reward,但它也需要调度,否则会变成高成本噪声。
Agent-RLVR 的风险是 guidance 可能变成拐杖。训练时有老师,测试时没有老师,模型是否真的学会策略,要看它能不能把 guidance 内化为搜索、定位、编辑和验证行为。如果只是学会"当 prompt 里出现具体文件名时去改这个文件",迁移就会很弱。
问题:Agent-RLVR 为什么比普通 RLVR 难?
答案:普通 RLVR 常常是单轮答案验证,agentic RLVR 是多轮环境交互。失败原因可能来自搜索、定位、编辑、测试、超时或环境,而最终 0/1 reward 不会告诉模型哪一步错。Agent-RLVR 用 guidance 降低探索难度,再用环境 reward 构造偏好和 reward model。
如果要用一句话复述这篇,我会说:Agent-RLVR 不是证明"RLVR 一定能解决 SWE",而是说明要把 RLVR 搬进 SWE,需要先解决正轨迹稀缺、失败归因困难和 guidance 设计。我的执行反馈工作刚好在问同一个底层问题:环境反馈什么时候是信号,什么时候是噪声。
11. RAGEN:多轮 agent RL 最怕学出自我重复
RAGEN 不是专门写 SWE 的,但它对理解 agent RL 很有帮助。它研究 multi-turn RL for LLM agents,并提出 StarPO 框架。alphaXiv 的 overview 对这篇很适合做第一遍阅读,因为它把 StarPO、Echo Trap、multi-turn collapse 这些概念先拆开讲,再回到论文实验。
传统 RLHF 或数学题 RL 常常是单轮:给 prompt,模型输出答案,环境/标注器给分。agent 不一样。agent 会观察环境、思考、行动,再观察,再行动。每一步都可能改变后续状态。
RAGEN 的 StarPO 把 trajectory 写成 state、thinking、actions、reward 的链路。这个建模很适合拿来解释 SWE agent:repo 是 state,模型的分析是 thinking,search/edit/test 是 actions,测试结果或最终通过是 reward。
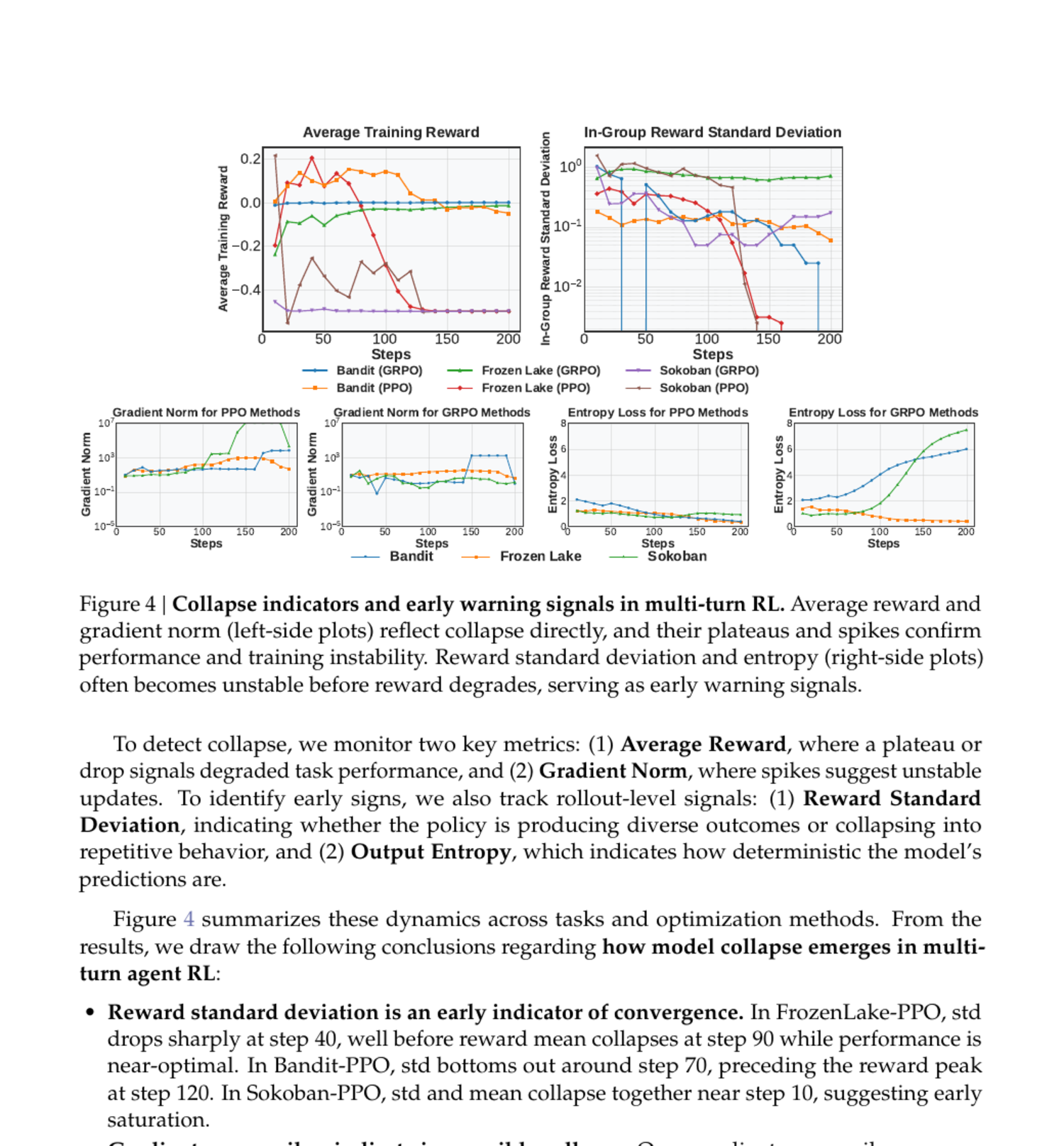
这张图是我读 RAGEN 时最想保留的。它没有只给最终 success rate,而是在看训练病灶。左侧几组图看 reward 和 gradient norm,右侧看 reward standard deviation 与 entropy。论文的核心观察是:多轮 agent RL 里,模型可能先涨 reward,随后 reward variability 掉下去、entropy 变窄、gradient norm 出现 spike,最后进入 Echo Trap。
Echo Trap 可以直觉理解成:模型学到了一套局部有奖励的说法或动作模式,然后不断重复它。它看起来更确定,实际上更窄。这个问题在 SWE 里太熟了:agent 反复 grep 同一个关键词,反复打开同一段文件,反复跑同一组测试,或者每次失败后都写类似的"我需要检查 X"但行动没有变化。日志里看起来很努力,策略上已经卡死。
RAGEN 的价值是给了几个诊断指标。reward 平均值不够看,因为它可能短期上升。reward standard deviation 下降,说明同一组 prompt 下 rollout 结果缺少区分;entropy 下降,说明输出分布变窄;gradient norm spike 说明更新开始不稳定。这些指标放到 SWE agent 上也可以改写成:工具调用多样性、文件访问多样性、测试运行分布、patch diff 大小、重复 action 比例。
论文提出 StarPO-S 来缓解这种问题。它保留高不确定性的 prompt,也就是同一 prompt 下不同 rollout 结果差异较大的样本。直觉上,这些样本最有学习价值:太简单的任务全对,没什么梯度;太难的任务全错,也没什么信号;有分歧的任务才说明模型处在会与不会之间。
StarPO-S 还使用 critic incorporation、trajectory filtering、decoupled clipping 等设计。对我来说,不需要把每个公式都背下来,但要记住它背后的训练哲学:agent RL 不能把所有 rollout 平等喂给模型。要挑那些能提供策略差异的轨迹,并监控多轮训练里的 collapse signals。
如果把 StarPO-S 翻译成 SWE 语言,它像是在说:训练集里最有价值的不是全对任务,也不是全错任务,而是那些同一个 issue 下模型有时能修好、有时修不好的任务。全对任务提供不了太多梯度,全错任务没有正轨迹,中间态任务才暴露策略差异。SWE agent 的版本可以是:同一个 repo issue 下,有的 rollout 找到正确文件,有的 rollout 反复 grep;有的 patch 只差一个边界条件,有的 patch 改错模块。这样的对比最适合做 preference、verifier 或 guidance。
RAGEN 还让我更重视 entropy 和 action diversity。一个 SWE agent 如果 reward 变高但工具调用越来越单一,未必是好事。它可能学会了某种局部模板,比如每次先 grep error,然后改第一个匹配文件。短期会过一些任务,长期会在不同仓库里崩。训练日志里如果只看 resolved rate,会错过这种策略收缩。
这让我对 "just scale RL" 保持警惕。agent RL 不是只看最终 reward 曲线,还要看轨迹长度、工具调用分布、重复动作比例、测试运行次数、失败日志类型、patch diff 大小。这些恰好是软件工程研究者更敏感的地方。
MazeBreaker 也能接到这条线。它表面上是 LLM 安全和多智能体攻击,但放到 agent RL 语言里,它研究的是多轮策略、环境反馈和路径优化。这个翻译比单纯说"我做过安全评测"更有训练组语感。
我还会把 RAGEN 当作一个提醒:不要以为显式 <think> 就等于有效推理。论文讨论 reasoning traces 可能缩水,也可能变成 hallucinated reasoning。SWE agent 的 "I will inspect the failing test" 也可能只是漂亮话,真正的证据要看它有没有打开正确文件、有没有运行合适测试、有没有把日志转成 patch 决策。
问题:RAGEN 对 SWE agent training 的最大提醒是什么?
答案:多轮 RL 的失败不一定表现为分数立刻下降,它可能先表现为策略变窄、重复动作变多、reward variance 下降、entropy 下降和 gradient spike。SWE agent 训练也应该监控工具调用多样性、文件访问分布、重复测试比例和失败类型,而不是只看最终 resolved rate。
如果要把这篇接回 To Run or Not to Run,我会这样说:执行反馈不只是 reward,它还会改变下一步 state。多轮环境里,错误反馈、冗余反馈和弱测试反馈都可能把 agent 推进 Echo Trap。研究执行反馈的边际价值,本质上是在研究哪些 observation 值得进入 agent 的训练和推理闭环。
12. DeepSWE:SWE RL 终于写成了工程 recipe
DeepSWE 是我觉得最像工程 recipe 的一份材料。它不只说"RL 提升了 SWE-bench",而是把环境、动作空间、reward、rollout 系统和训练 trick 都摆出来。
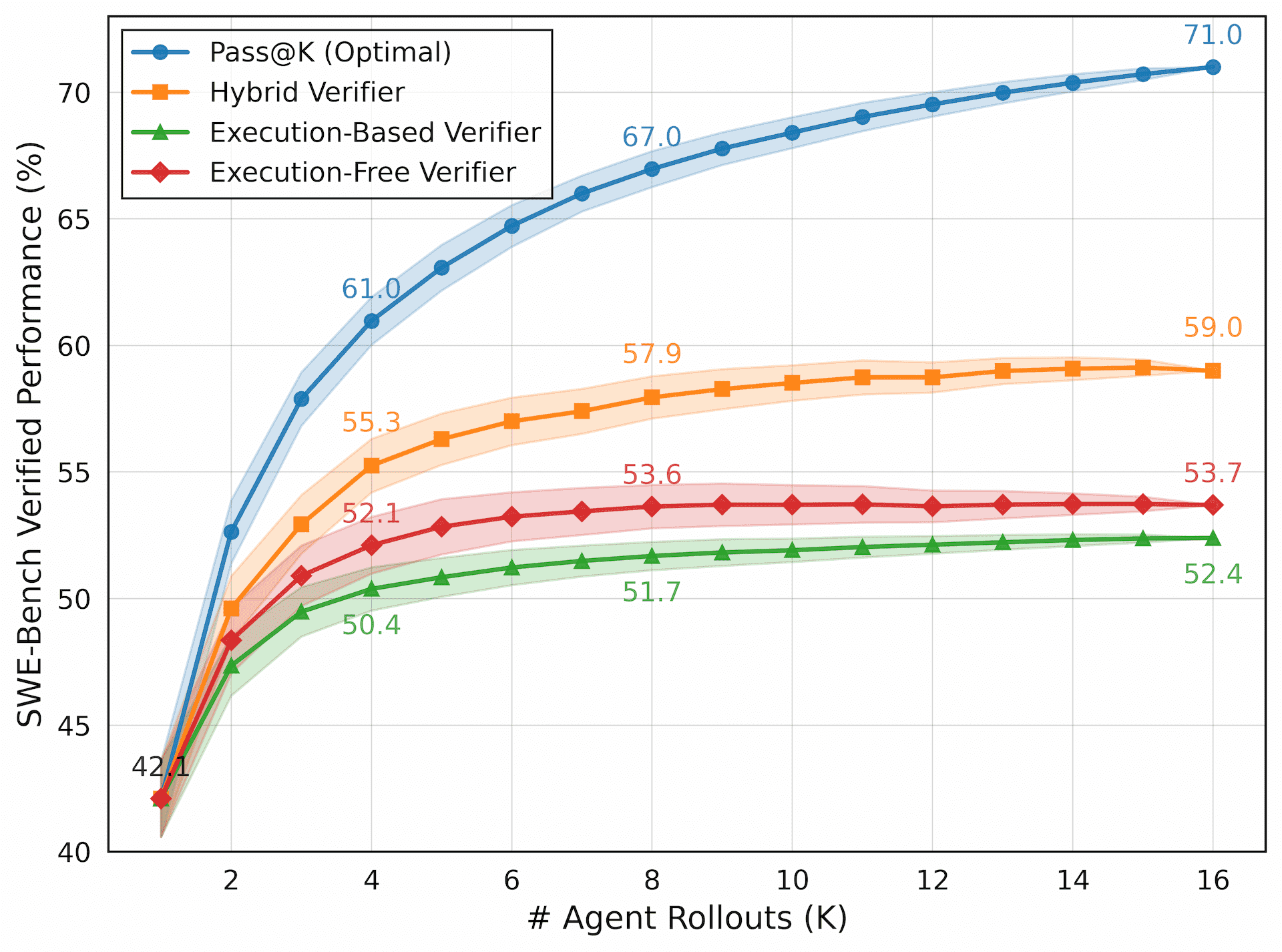
这张图很适合解释为什么 SWE agent 不能只谈单次 Pass@1。蓝线 Pass@K 是"如果候选轨迹里只要有一个对的,我们就总能挑出来"的理想上界;橙线 hybrid verifier 才更接近现实,因为它要在 execution-based verifier 和 execution-free verifier 之间做折中。图里最有意思的不是 59.0% 这个点本身,而是 K 从 1 到 8 时提升很快,后面逐渐变平。这说明多 rollout 有价值,但收益不是无限的。
公开博客里的关键信息包括:
- 从 Qwen3-32B 出发;
- 使用 4.5K R2E-Gym tasks;
- 用 64 H100 训练 6 天;
- 动作空间包括 bash、search、file editor、finish/submit;
- reward 是稀疏 0/1:选定测试在时限内通过为 1,否则为 0;
- 使用 GRPO++;
- 通过 Kubernetes 管理大规模环境 rollout;
- 讨论 compact filtering、training-time scaling 和 hybrid test-time scaling;
- 报告 Pass@1 42.2%,hybrid test-time scaling 后 SWE-Bench Verified 约 59%。
这篇的价值在于它把 SWE RL 的麻烦讲得很具体。环境启动慢,依赖安装慢,测试 flaky,轨迹太长,成功样本少,超时样本多,reward collapse,teacher trajectory 未必好。每一个问题都不是抽象算法词,而是训练系统会真实遇到的工程事故。
我最想记住的是 compact filtering。长轨迹不一定更有价值。很多超长轨迹只是模型在迷路,或者在失败后不断补救。把这些样本直接喂给 RL,可能会强化坏习惯。这个判断和 To Run or Not to Run 很近:执行、搜索、编辑都应该被看成有成本的动作,而不是越多越好。
DeepSWE 也提醒我,SFT teacher trajectory 不一定总是好东西。强模型生成的轨迹可能很漂亮,但也可能冗长、依赖隐式知识、不适合小模型模仿。冷启动 RL 如果环境和 reward 做得好,反而可能学出更适合自身能力的策略。
我会把 DeepSWE 的 recipe 拆成五个问题。
第一,state 给什么。SWE agent 的 state 不只是 issue,还包括工作目录、文件内容、历史命令、测试日志和已做修改。state 太短,agent 没记忆;state 太长,KV cache 和噪声都上来。
第二,action 怎么定义。DeepSWE 的 action space 包括 bash、search、file editor、finish/submit。动作空间太自由,探索空间爆炸;太受限,又可能挡住真实修复路径。一个好的 ACI 本身就是训练设计。
第三,reward 怎么给。稀疏 0/1 reward 简洁,但 credit assignment 很难。通过测试才给 1,失败全是 0,这对训练系统提出很高要求:要有足够 rollout、多样任务、过滤策略和稳定优化。
第四,rollout 怎么跑。DeepSWE 用 Kubernetes 管理大规模环境,这说明 SWE RL 是系统工程。环境吞吐不够,训练就等 rollout;环境状态不干净,reward 就不可信;日志太长,context 就被污染。
第五,test-time scaling 怎么用。Pass@K 是上界,hybrid verifier 是现实。多采样只有在 verifier 能选对时才真正变成部署收益。否则只是生成更多候选 patch,然后更难挑。
DeepSWE 还把一个常被忽略的问题讲清楚了:SWE RL 的训练数据不是静态表格,而是一堆会超时、会污染工作目录、会产生日志、会占用集群资源的环境进程。用 Kubernetes 管 rollout,不是工程炫技,而是为了让 RL 真的跑得动。没有足够环境吞吐,policy update 会一直等 rollout;环境不隔离,reward 会被脏状态污染;日志不压缩,上下文会被失败输出塞满。
GRPO++ 这类算法名当然要知道,但我不会把它当成唯一重点。DeepSWE 里更值得记的是算法和环境一起设计:稀疏 reward 要配多 rollout,长轨迹要过滤,test-time scaling 要配 verifier,ACI 要限制动作空间,训练系统要能承受失败样本。否则把任何 RL 算法套到 SWE 上都容易得到很漂亮但不可复现的曲线。
我喜欢 DeepSWE 的地方在于它足够接地气:它承认 SWE RL 里会有超时、长尾 rollout、compact 质量问题、teacher trajectory 问题、verifier 问题。它不像有些报告只把 RL 写成"我们用了 GRPO,然后分数涨了"。
如果要把我的研究接到 DeepSWE,我会这样说:
- CodeAnchor 降低 repo navigation 的探索空间。
- To Run or Not to Run 控制执行反馈预算。
- Chain-Tracking 帮助判断成功 patch 是否有因果链。
- RepoRescue 提供依赖漂移环境。
- SWE-OpenHarmony 提供垂域可执行任务。
这些不是模型外的"应用经验",而是 SWE RL recipe 里会影响训练信号质量的部件。
问题:DeepSWE 为什么像一份工程 recipe?
答案:它没有只说"用 RL 提升 SWE-bench",而是把 state、action、reward、ACI、环境 rollout、轨迹过滤、Kubernetes 吞吐和 test-time verifier 都写出来。它告诉我 SWE agent RL 的单位不是一条样本,而是一个可执行、可隔离、可验证、可重复采样的环境过程。
DeepSWE 给我的最终 takeaway 是:SWE agent RL 的核心不是某个单独算法名,而是 data、environment、reward、rollout system、filtering 和 verifier 组成的一整套闭环。任何一个环节脏了,模型都会学到奇怪东西。
13. 把这些论文压成一个训练闭环
读完上面这些材料,我会把 code model / SWE agent training 压成一个闭环:
| 阶段 | 在训练里做什么 | 对应材料 | 我的工作怎么接 |
|---|---|---|---|
| base pretraining | 学语言、代码、数学、基础推理 | GLM-5、Kimi K2、DeepSeek-V4 | 需要理解 loss、optimizer、data mixture |
| long-context / repo training | 学 repo-level 结构和长证据链 | GLM-5.2、IQuest-Coder、DeepSeek-V4 | CodeAnchor、AtomicCommitBench |
| SFT / trajectory imitation | 学工具使用和修复流程 | SWE-Gym、SWE-Dev、DeepSWE | 高质量 agent trajectories |
| verifier / preference | 用测试、编译、review 构造 chosen/rejected | SWE-Gym、Agent-RLVR | To Run、Chain-Tracking |
| RLVR / agent RL | 在环境里 rollout,按 reward 更新 | Agent-RLVR、RAGEN、DeepSWE | 可执行任务、反馈调度 |
| inference-time scaling | 多采样、多 rollout、verifier rerank | SWE-Gym、SWE-Dev、DeepSWE | 执行预算、停止策略 |
| failure flywheel | 分析失败,回流数据和环境 | SWE-smith、RAGEN | RepoRescue、SWE-OpenHarmony |
这个闭环比单独背每篇论文更有用。因为面试里真正有价值的问题通常不是"你读过哪篇",而是"你知道这些东西怎样连起来吗"。
我会坚持一个定位:我不是把自己伪装成已经负责过千卡 pretraining 的人。更准确的说法是,我站在 code agent training 的任务与反馈侧,正在补齐训练侧共同语言。代码基模想做 agentic engineering,就必须有人把真实软件工程问题变成可训练、可验证、可复现的环境和数据。
如果用 alphaXiv 或论文页面复习,我会按这个顺序读,而不是从头到尾硬啃。
第一遍只看 abstract、Figure 1、method overview 和 result table,先回答"这篇到底想改变训练闭环里的哪一环"。比如 DeepSeek-V4 改的是长上下文经济性,SWE-Gym 改的是训练环境,Agent-RLVR 改的是稀疏 reward 下的探索。
第二遍盯图。图不是装饰。GLM-5 的训练 pipeline 告诉你 post-training 阶段如何排布;Qwen3-Coder 的曲线告诉你 code RL 不是一个榜单点;SWE-Dev 的 test pipeline 告诉你 verifier 从哪来;RAGEN 的 collapse indicators 告诉你多轮 RL 会怎么病。
第三遍找训练信号。每篇都问同一个问题:输入是什么,动作是什么,reward 或 preference 从哪来,哪些 token 计 loss,失败样本怎么处理,环境成本谁承担。能回答这些,才算真正读进去了。
第四遍找风险。长上下文有噪声,合成数据有分布偏移,测试 reward 会被 hack,guidance 会泄漏答案,多 rollout 会遇到 verifier 选择错误。论文最值得学的地方往往不是它说自己多强,而是它暴露了哪类训练问题。
第五遍接回自己的工作。读完每篇都要能说清自己能补哪一环:CodeAnchor 补结构入口,To Run 补反馈预算,RepoRescue 补可执行修复环境,AtomicCommitBench 补变更轨迹,SWE-OpenHarmony 补垂域任务。这样复习才不会变成背模型新闻。
14. 一些可以直接拿去用的回答
如果被问:"为什么 pretraining loss 下降不等于 SWE-bench 提升?"
答案:
pretraining loss 是 token-level NLL,衡量模型对下一个 token 分布的拟合。SWE-bench 是长程 agent task,中间有 repo retrieval、bug localization、patch editing、test execution、log understanding 和 iterative repair。loss 更低能提高基础代码能力,但 resolved rate 还依赖工具使用、上下文组织、verifier 和反馈调度。
如果被问:"1M context 能不能解决 repo-level coding?"
答案:
1M context 提高上限,但不会自动解决 repo-level coding。长上下文带来 KV cache、prefill、attention FLOPs 和噪声问题。真实仓库任务需要结构检索、deterministic anchors、context compression 和 execution feedback。否则模型只是看到了更多 token,不代表找到了关键证据。
如果被问:"SWE agent 为什么适合 RLVR?"
答案:
因为代码任务有天然 verifier,比如 unit tests、编译和运行输出,可以把结果转成 reward 或 preference。但难点是 reward 稀疏、episode 长、环境贵、credit assignment 难。最终测试通过不能告诉模型哪一步有贡献,所以还需要 guidance、trajectory filtering、verifier 质量控制和执行预算调度。
如果被问:"你的 SE 背景怎么接到 code model training?"
答案:
我的研究集中在真实软件工程 agent 的任务侧闭环:仓库级上下文、执行反馈、benchmark、verifier、轨迹和低泄漏环境。现在 code model 从 HumanEval 走向 repo-level tool-use agent,这些能力需要真实任务和可靠反馈。我补齐训练基础后,可以把这些 SE 资产接到 post-training、RLVR、eval 和 data flywheel 里。
15. 我接下来会怎么复习
我会按三层复习,不再把论文当成孤立材料。
第一层是训练地基。能讲清 cross entropy、perplexity、AdamW、warmup、loss spike、attention、KV cache、MoE、FSDP/ZeRO、SFT、DPO、GRPO、RLVR。每个概念都要能说出一个代码 agent 场景里的例子。
第二层是模型报告。GLM-5/5.2 看 long-context agentic engineering 和 slime;DeepSeek-V4 看 1M context 的经济性;IQuest-Coder 看 code-flow multi-stage training;Qwen3-Coder 看大规模并行环境;Kimi K2 看 MuonClip 和 agentic data synthesis。
第三层是 SWE agent 训练。SWE-Gym 看可执行训练环境;SWE-smith 看规模化任务合成;SWE-Dev 看 training/inference scaling;Agent-RLVR 看 reward sparsity 和 guidance;RAGEN 看 multi-turn RL 的训练病灶;DeepSWE 看完整工程 recipe。
最后,我会把自己的工作统一翻译成训练语言:
- CodeAnchor:repo-level structural anchoring。
- To Run or Not to Run:execution feedback scheduling。
- RepoRescue:dependency-drift repair environment。
- AtomicCommitBench:patch-intent and commit trajectory data。
- Chain-Tracking:trajectory credit assignment over CI/log/code changes。
- SWE-OpenHarmony:domain-specific executable agent benchmark。
这不是为了把所有东西硬贴到大模型上,而是因为前沿代码基模确实在往这个方向走。真实软件工程越进入训练闭环,软件工程研究者越不应该只站在评测终点看热闹。
参考材料
alphaXiv 的 .md 入口很好用,适合直接喂给 AI 做逐段问答。我自己复习时会先看页面和图,再用 Markdown 入口追细节。
- GLM-5: alphaXiv, AI Markdown, GitHub
- GLM-5.2: alphaXiv, AI Markdown, official blog
- DeepSeek-V4: alphaXiv, AI Markdown, official release
- IQuest-Coder-V1: alphaXiv, AI Markdown
- Qwen3-Coder: official blog
- Kimi K2: alphaXiv, AI Markdown
- SWE-Gym: alphaXiv, AI Markdown
- SWE-smith: alphaXiv, AI Markdown
- SWE-Dev: alphaXiv, AI Markdown
- Agent-RLVR: alphaXiv, AI Markdown
- RAGEN: alphaXiv, AI Markdown
- DeepSWE: Together AI blog